Qdrant 向量数据库性能优化,系统内存占用降低 75%
起因
Chat2Report 上线之后,服务器成本就一直让我头疼。项目赚不了多少钱,每个月账单却要 400 多。问题的根源是向量数据库太吃内存了。。。
第一版大概有 14 万份财报,全部向量化塞进 Qdrant 之后,内存直接干到 44G 以上。偏偏财报还在每天不停地增加,新的解析完就嵌入,内存一路往上涨,根本停不下来。没办法,只好咬牙买了台 64G 内存的服务器。
技术债务
当初选嵌入模型的时候,用的是 Jina Embeddings v3。5.7 亿参数、8K 输入长度、多语言支持,在 MTEB 上的性能甚至超过了 OpenAI 和 Cohere 最新的专有嵌入模型。最关键的是便宜,当时每百万 token 才 $0.02(现在已经涨到 $0.05 了),要向量化这么多财报,感觉赚到了。
为了追求检索准确率,我把嵌入维度设成了 1024,就是这个决定,给后来的高额服务器费用埋下了雷。
后来也试过用 Qdrant 的量化配置把原始向量存到磁盘,内存是降了一些,但还是很高。现在回头想想,怎么当时就没想到把嵌入维度降下来呢?维度低一点,检索准确率其实没差多少(这个后面我会单独写一篇聊),真想回去扇自己两巴掌。
启发
后来 Jina 发布了 CLIP v2,我顺手把它的新闻稿仔细看了一遍。Jina.ai 每次出新模型都会配套发论文,而且模型全部开源,这点我一直很欣赏。
也是通过这篇新闻稿,我才搞清楚一件事:嵌入维度降低,检索精度掉的那点损失基本可以忽略不计,从成本角度来说完全值得。
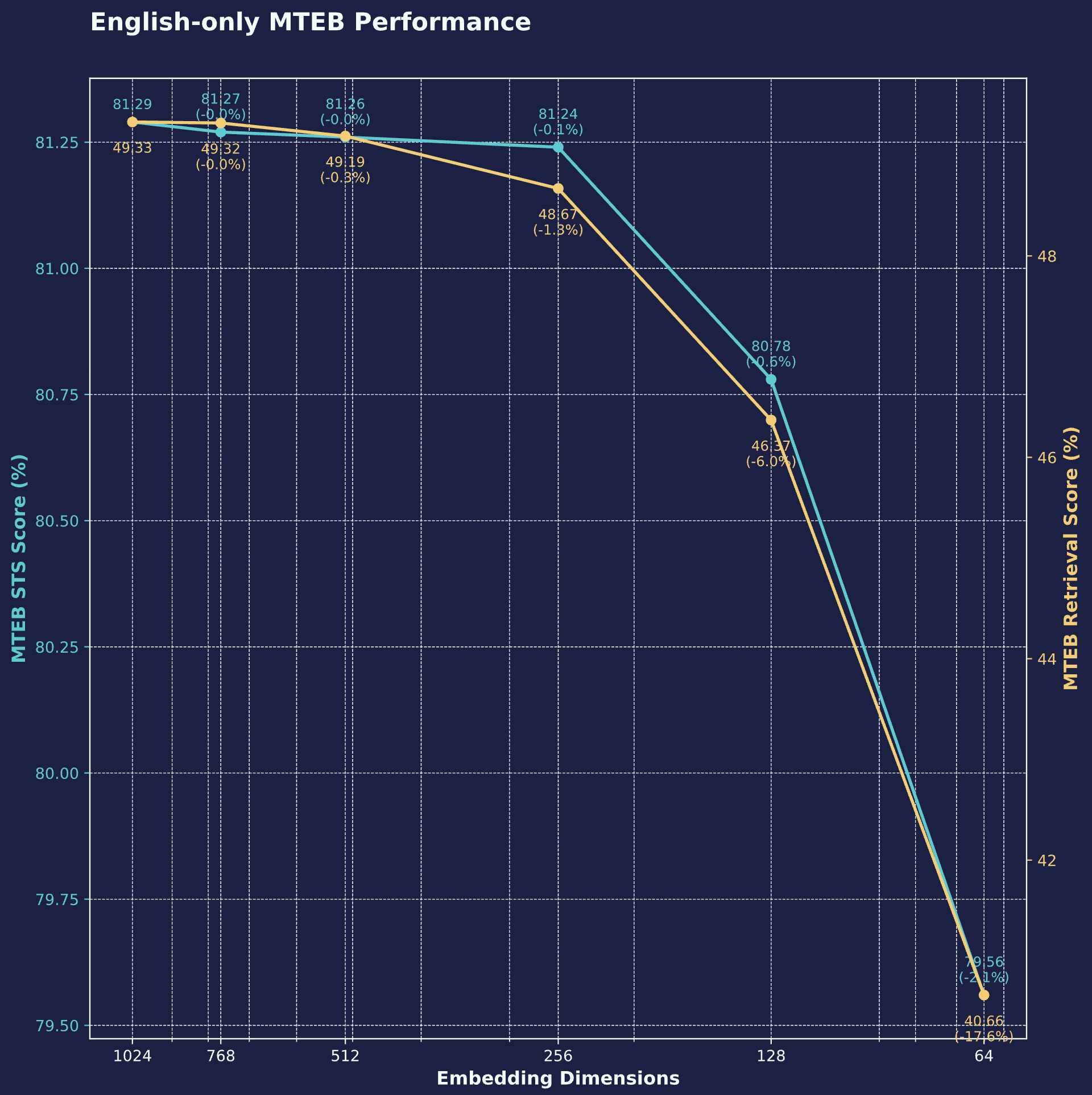
下图是纯文本检索在英语 MTEB 基准测试里的数据,维度从 1024 降到 256,语义相似度和检索性能分别只下降了 0.1% 和 1.2%,完全能接受。256 维度基本上是最甜的点位了,再往下降就不太划算了。
优化方向
几千万条向量数据要全部重新嵌入,想想就头大。不过方向已经定了,剩下的就是时间问题,主要从三个方向来优化:
- 降低嵌入维度:从 1024 压缩到 256。
- 标量量化:Qdrant 量化精度设为 int8,精度损失最小,压缩比有 4x。
- 原始向量落盘:把原始向量存到磁盘,内存压力能降不少。
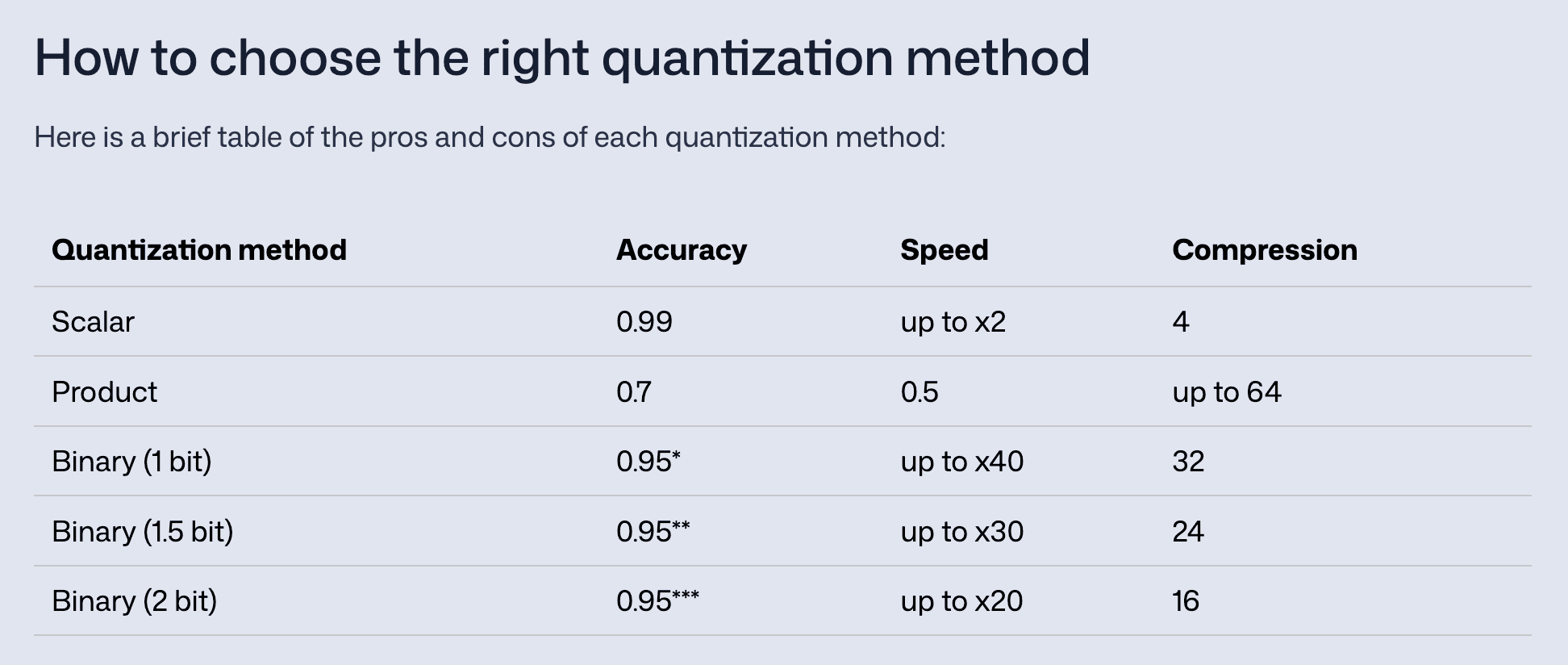
上面这些方案在 Qdrant 官方文档 官方文档里都有详细说明,还列出了各方案的优缺点对比,非常良心。所以说,没事多看看官方文档,真的是最笨也最有用的方法。
最后效果
效果还是很明显的,优化之后 2600 多万条向量数据只占了 9.1 G 内存,比之前降了 75% 以上。






