怎么快速实现一个 ChatPDF
好奇心
最近在研究 RAG 相关的技术,刚好看到 ChatPDF(一款像使用 ChatGPT 一样轻松地与 PDF 进行对话,还支持引用溯源的应用), 它突破了 LLM 上下文的限制,可以和长达几百页的 PDF 文件进行交互,很好奇它是怎么实现的。

架构设计
开始之前先说明一下,这篇文章假设你对嵌入模型、重排序模型、向量数据库、LLM 这些概念有基本了解,就不展开讲了。
核心原理
在实现 ChatPDF 之前,我最大的疑惑是 LLM 怎么知道内容来自 PDF 的哪一页?
分析下来其实很简单,核心分三步:
- 解析分块:将 PDF 文档切分成小块,为每一块打上标记(页码 + bbox 边界框)
- 检索返回:LLM 检索时,把相关文本块连同标记一起返回
- 前端高亮:前端根据页码和 bbox 坐标,在 PDF 上精准定位并高亮显示引用区域
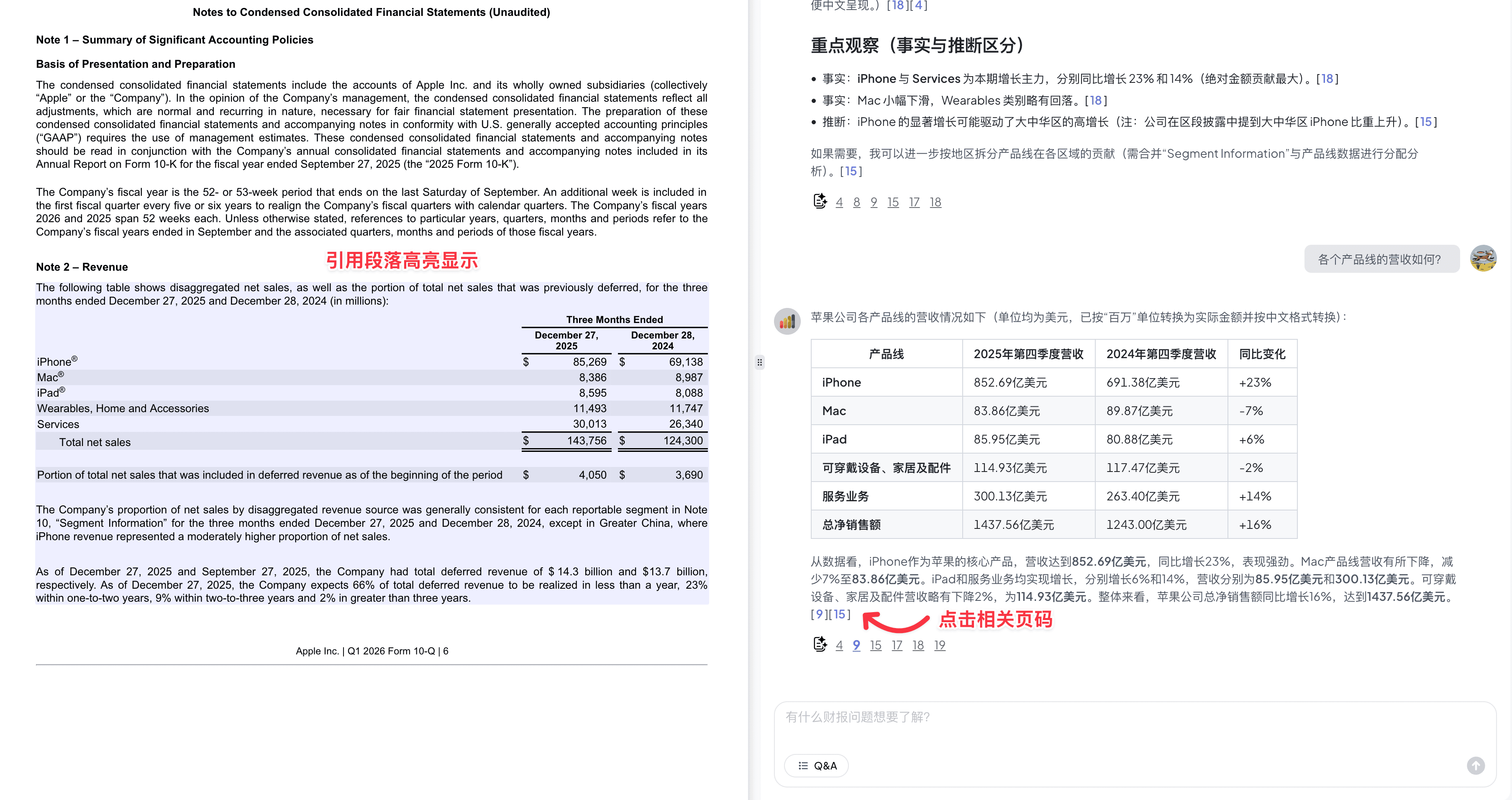
这样就实现了下面这种效果:
这是我后面开发的产品 Chat2Report,里面有一个财报模块也采用了 RAG 技术,但是明显比 ChatPDF 的回答效果要好不少。
系统流程
总结下来 ChatPDF 包括以下几个关键环节:
- 文档处理管道:解析 PDF 文档 → 提取文本 → 分块 → 保留元数据(页码/bbox)
- 向量存储:分块向量化 → 存入向量数据库
- 检索管道:用户提问 → 向量相似性检索 → 重排序精选
- 生成回答:使用检索的内容作为上下文 → LLM 生成带引用的答案
为了提高检索准确率,引入了重排序模型(Reranker Model),用于第二阶段精排。
技术选型
为实现上述流程,需要选择合适的工具。选型原则:性能够用 + 成本可控 + 易于集成。
| 组件 | 选择 | 理由 | 对应流程环节 |
|---|---|---|---|
| 文档解析 | Docling | 支持智能分块、保留完整元数据(页码/bbox/表格结构) | 文档处理管道 |
| RAG框架 | LlamaIndex | 专为RAG设计,集成所有组件,开箱即用 | 全流程编排 |
| 嵌入模型 | Jina Embeddings v3 | $0.02/百万token,MTEB性能超OpenAI,支持8192 token | 向量化 |
| 重排序 | Jina Reranker v2 | $0.02/百万token,支持100+语言,性能顶尖 | 检索精排 |
| 向量数据库 | Qdrant | Rust开发性能强,文档详细,支持混合检索 | 向量存储 |
| LLM | DeepSeek | 性价比高,幻方量化出品,推理质量优秀 | 答案生成 |
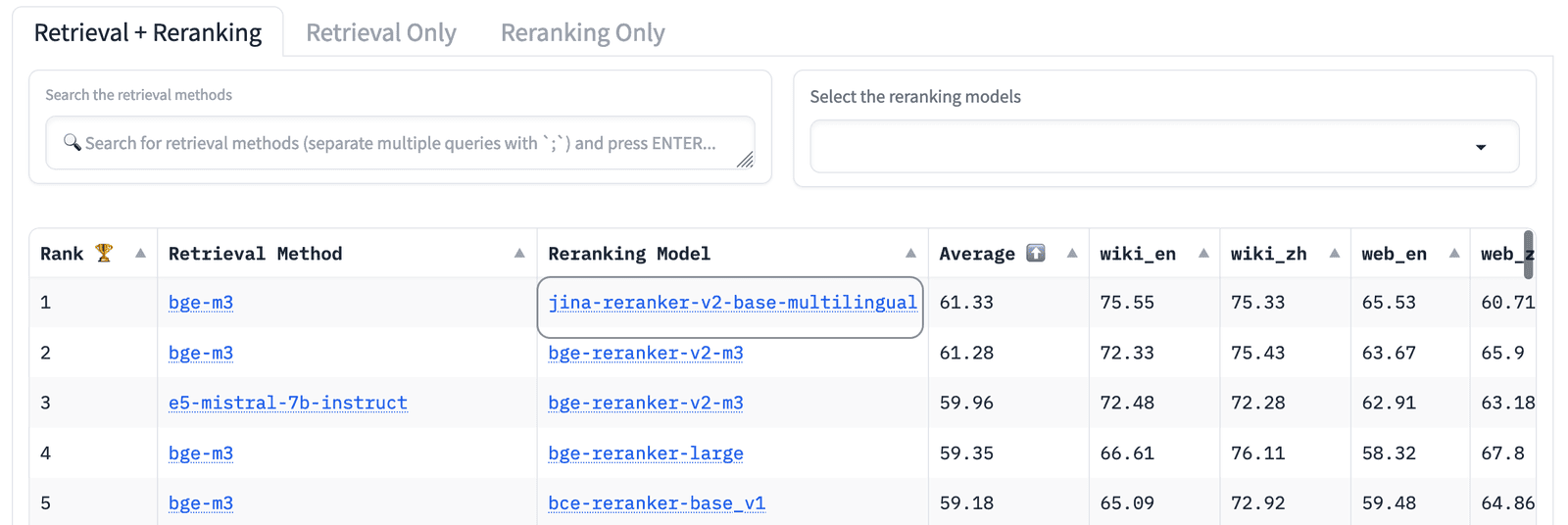
整套方案以 Jina 为核心(嵌入+重排序),统一定价 $0.02/百万token,相比 OpenAI 的 text-embedding-3-large($0.13/百万token)节省 85% 成本。
核心概念
在动手写代码之前,需要理解几个关键概念,这些概念贯穿整个实现过程。
向量嵌入基础
什么是向量嵌入?
向量嵌入是将文本转换为数字向量的过程。例如,"苹果公司发布新产品"这句话会被转换为一个 256 维的向量 [0.23, -0.45, 0.67, ...]。相似的文本会产生相似的向量。
为什么选择 256 维?
- 精度够用:256 维在检索准确率上与 768 维、1024 维相比损失很小(<2%)
- 存储节省:相比 768 维节省 67% 存储空间
- 检索更快:向量维度越低,相似度计算越快
其实最开始选择的是 1024 维,后面吃了大亏,所以重新编辑更新了这篇文章。后面有讲如何选择嵌入维度。
余弦相似度 vs 其他距离度量
| 度量方式 | 适用场景 | 优点 | 缺点 |
|---|---|---|---|
| COSINE | 文本嵌入、语义搜索 | 对长度不敏感,符合语义直觉 | 需要向量非零 |
| EUCLID | 图像特征、坐标数据 | 直观,保留长度信息 | 受向量长度影响大 |
| DOT | 推荐系统、评分预测 | 计算快,保留长度信息 | 不对称,需要归一化 |
| MANHATTAN | 高维稀疏向量、异常值场景 | 快速,对异常值鲁棒 | 不适合语义搜索 |
选择 COSINE(余弦相似度),是因为在 NLP 领域,它更符合人类对"相似"的理解,只关注方向而不关注长度。
分块策略
为什么需要分块?
PDF 文档可能有几百页,但 LLM 上下文窗口有限,向量检索也需要在合适的维度上进行。太大的块会包含无关信息,太小的块会丢失上下文。
HierarchicalChunker 智能分块
Docling 的 HierarchicalChunker 会:
- 保持段落完整性,不在句子中间切断
- 根据文档结构(标题、章节)进行分块
- 自动关联同一标题下的内容块
元数据的重要性
每个块都会保留:
page:页码,用于引用溯源bbox:边界框坐标,标记文本在页面中的精确位置headings:标题层级,帮助理解上下文
这些元数据是实现点击页码跳转+高亮显示的关键。
RAG 检索流程
两阶段检索
粗排(Retrieval):
similarity_top_k=5- 在向量数据库中快速检索出 5 个最相似的文档块
- 基于向量余弦相似度排序
- 速度快但精度有限
精排(Rerank):
top_n=3- 使用专门的重排序模型对 5 个候选进行重新打分
- 考虑更复杂的语义关系
- 从 5 个中精选出 3 个最相关的
为什么需要重排序?
向量检索是基于嵌入模型的,可能会漏掉一些语义细节。重排序模型专门训练用于判断查询-文档的相关性,能显著提升最终结果的质量。
检索参数调优
similarity_top_k:初筛候选数量,建议 5-10top_n:最终使用数量,建议 3-5- 两者比例通常是 2:1 或 3:1
文本 & 图片提取
Docling 的输出格式
Docling 提取 PDF 后可以导出为:
JSON 格式(推荐用于引用溯源):
- 页面编号 (page_no)
- 布局信息(边界框 bbox)
- 字符范围 (charspan)
- 文档层次结构
- 图片和表格的完整元数据
Markdown 格式(推荐用于纯文本场景):
- 文本内容和基本格式化
- 标题层级
- 表格结构(简化版)
- 图片引用
这里选择 JSON 格式,因为它包含完整的位置信息,是实现精准引用溯源的基础。
多模态扩展方向
示例代码未展示图片嵌入,实际应用中有两种方案:
- 文本化方案:提取图片 → 多模态 LLM 生成描述 → 与文本一起嵌入
- 多模态嵌入:使用多模态嵌入模型直接嵌入图片和文本
实现
环境准备
安装依赖:
pip install llama-index-core llama-index-embeddings-jinaai llama-index-llms-openai-like \
llama-index-postprocessor-jinaai-rerank llama-index-vector-stores-qdrant \
llama-index-readers-docling llama-index-node-parser-docling \
qdrant-client python-dotenv tiktoken
配置环境变量(.env 文件):
DEEPSEEK_BASE_URL=https://api.deepseek.com/v1
DEEPSEEK_API_KEY=your_deepseek_key
JINA_API_KEY=your_jina_key
启动 Qdrant:
docker run -p 6333:6333 qdrant/qdrant
实现步骤概览
整个实现分为 5 个步骤,每个步骤对应代码中的一个关键部分:
| 步骤 | 功能 | 核心代码 | 输出 |
|---|---|---|---|
| Step 1 | 配置 LLM、嵌入、重排序模型 | llm = OpenAILike(...) | 模型实例 |
| Step 2 | 解析 PDF、智能分块、提取元数据 | process_pdf_to_documents() | Document 列表 |
| Step 3 | 创建向量索引、存储到 Qdrant | VectorStoreIndex.from_documents() | VectorStoreIndex |
| Step 4 | 配置查询引擎、提示词 | index.as_query_engine() | QueryEngine |
| Step 5 | 执行查询、展示结果 | query_engine.query() | 带引用的答案 |
完整代码
下面是完整的实现代码,包含详细的注释说明每个步骤的作用。代码可以直接运行,建议按照上面的步骤概览逐步理解。
import os
import pathlib
import tiktoken
from typing import List, Tuple
from dotenv import load_dotenv
from llama_index.core import (
Document,
PromptTemplate,
Settings,
StorageContext,
VectorStoreIndex,
)
from llama_index.embeddings.jinaai import JinaEmbedding
from llama_index.llms.openai_like import OpenAILike
from llama_index.postprocessor.jinaai_rerank import JinaRerank
from llama_index.vector_stores.qdrant import QdrantVectorStore
from llama_index.node_parser.docling import DoclingNodeParser
from llama_index.readers.docling import DoclingReader
from qdrant_client.models import Distance, VectorParams
from qdrant_client import QdrantClient
root_path = pathlib.Path(__file__).parent
load_dotenv()
# ============================================================
# 第一步: 配置大语言模型 (LLM)
# ============================================================
# 使用 Deepseek 作为推理模型,负责根据检索到的文档生成最终答案
llm = OpenAILike(
api_base=os.getenv("DEEPSEEK_BASE_URL"),
api_key=os.getenv("DEEPSEEK_API_KEY"),
model="deepseek-chat",
temperature=0.0,
max_tokens=1024,
context_window=8192,
is_chat_model=True,
timeout=60,
)
Settings.llm = llm
Settings.tokenizer = tiktoken.encoding_for_model("gpt-4o").encode
# ============================================================
# 第二步: 配置嵌入模型 (Embedding Model)
# ============================================================
# 文本嵌入模型: 将文档文本转换为 256 维向量,用于存储到向量数据库
text_embed_model = JinaEmbedding(
api_key=os.getenv("JINA_API_KEY"),
model="jina-embeddings-v3",
embed_batch_size=32,
dimensions=256,
task="retrieval.passage", # 针对文档段落优化
)
# 查询嵌入模型: 将用户问题转换为 256 维向量,用于检索相似文档
query_embed_model = JinaEmbedding(
api_key=os.getenv("JINA_API_KEY"),
model="jina-embeddings-v3",
embed_batch_size=32,
dimensions=256,
task="retrieval.query", # 针对查询优化
)
# ============================================================
# 第三步: 配置重排序模型 (Reranker)
# ============================================================
# 重排序模型: 对初步检索结果进行精排,提高最相关文档的排名
jina_rerank = JinaRerank(
api_key=os.getenv("JINA_API_KEY"),
model="jina-reranker-v2-base-multilingual",
top_n=3, # 重排序后保留前 3 个最相关的文档
)
# ============================================================
# 第四步: 连接向量数据库 (Qdrant)
# ============================================================
# Qdrant: 存储文档向量,支持高效的相似度搜索
qdrant = QdrantClient(host="localhost", port=6333)
# ============================================================
# 核心函数 1: 初始化向量存储
# ============================================================
def init_vector_store(collection_name: str) -> Tuple[QdrantVectorStore, StorageContext]:
"""
初始化向量存储和存储上下文
功能说明:
- 创建 Qdrant 向量存储的连接
- 配置 LlamaIndex 的存储上下文,用于后续索引创建
Args:
collection_name: Qdrant 集合名称
Returns:
Tuple[QdrantVectorStore, StorageContext]: 向量存储和存储上下文的元组
"""
vector_store = QdrantVectorStore(client=qdrant, collection_name=collection_name)
storage_context = StorageContext.from_defaults(vector_store=vector_store)
return vector_store, storage_context
# ============================================================
# 核心函数 2: 确保集合存在
# ============================================================
def ensure_collection_exists(collection_name: str) -> bool:
"""
确保 Qdrant 集合存在,如果不存在则创建
功能说明:
- 检查指定的集合是否已存在
- 如果不存在,创建新集合并配置向量参数:
* size=256: 向量维度为 256 (与嵌入模型的 dimensions 参数一致)
* distance=COSINE: 使用余弦相似度计算文档相似性
Args:
collection_name: Qdrant 集合名称
Returns:
bool: True 表示新创建的集合, False 表示集合已存在
"""
if not qdrant.collection_exists(collection_name):
qdrant.create_collection(
collection_name=collection_name,
vectors_config=VectorParams(size=256, distance=Distance.COSINE),
)
return True
return False
# ============================================================
# 核心函数 3: PDF 文档处理
# ============================================================
def process_pdf_to_documents(file_path: str) -> List[Document]:
"""
处理 PDF 文件并转换为 LlamaIndex Document 列表
功能说明:
这个函数完成三个关键步骤:
1. 读取 PDF: 使用 Docling 解析 PDF 的文本、表格、图片等内容
2. 分块 (Chunking): 将长文档切分为适合嵌入的小块
3. 元数据提取: 保留页码、位置等信息,用于后续引用溯源
Args:
file_path: PDF 文件路径
Returns:
List[Document]: Document 对象列表,每个对象包含文本和元数据
"""
# 步骤 1: 读取 PDF 文件
# DoclingReader 可以解析复杂的 PDF 结构 (表格、图片、公式等)
reader = DoclingReader(export_type=DoclingReader.ExportType.JSON)
docs = reader.load_data(file_path)
# 步骤 2: 文档分块 (Chunking)
# DoclingNodeParser 使用 HierarchicalChunker 进行智能分块:
# - 保持段落完整性
# - 根据文档结构 (标题、章节) 进行分块
# - 避免在句子中间切断
node_parser = DoclingNodeParser()
nodes = node_parser.get_nodes_from_documents(docs)
# 打印分块结果,理解文档如何被切分
print("\n" + "=" * 70)
print("文档分块结果")
print("=" * 70)
print(f"总节点数: {len(nodes)} 个")
print(f"平均每块长度: {sum(len(n.text) for n in nodes) // len(nodes)} 字符")
print(f"最小块长度: {min(len(n.text) for n in nodes)} 字符")
print(f"最大块长度: {max(len(n.text) for n in nodes)} 字符")
# 展示第一个节点的详细信息
if nodes:
first_node = nodes[0]
print("\n第一个节点详情:")
print(f" 文本长度: {len(first_node.text)} 字符")
print(f" 文本预览: {first_node.text[:150]}...")
print(f" 元数据: {first_node.metadata}")
print("=" * 70 + "\n")
# 步骤 3: 转换为 LlamaIndex Document 格式
documents = []
for node in nodes:
# 提取块级元数据 (用于引用溯源)
# - page: 页码,用于在答案中标注信息来源
# - bbox: 边界框坐标,标记文本在页面中的位置
# - headings: 标题层级,帮助理解文本的上下文
metadata = {
"page": str(node.metadata["doc_items"][0]["prov"][0]["page_no"]),
"bbox": node.metadata["doc_items"][0]["prov"][0]["bbox"],
"headings": node.metadata.get("headings", []),
}
llama_document = Document(
text=node.text,
metadata=metadata,
text_template="Metadata: {metadata_str}\n-----\nContent: {content}",
)
documents.append(llama_document)
return documents
# ============================================================
# 核心函数 4: 创建或加载向量索引 (主流程编排)
# ============================================================
def create_or_get_index():
"""
创建或获取现有的向量存储索引
功能说明:
这是整个 RAG 系统的核心流程编排函数,负责:
1. 初始化向量存储连接
2. 检查集合是否存在
3. 如果是新集合:
- 处理 PDF 文档
- 进行向量嵌入 (关键步骤)
- 存储到 Qdrant
4. 如果集合已存在:
- 直接加载现有索引
Returns:
VectorStoreIndex: 向量存储索引对象,用于后续查询
"""
collection_name = "chatpdf"
# 步骤 1: 初始化向量存储
vector_store, storage_context = init_vector_store(collection_name)
# 步骤 2: 检查并创建集合
is_new_collection = ensure_collection_exists(collection_name)
if is_new_collection:
# 分支 A: 新集合 - 需要处理文档并创建索引
print("检测到新集合,开始处理文档...")
# 这里解析 A 股一家上市公司的季报作为示例
file_path = f"{str(root_path)}/data/disu.pdf"
documents = process_pdf_to_documents(file_path)
print(f"文档处理完成,共 {len(documents)} 个文档块")
# 关键步骤: 向量嵌入
# VectorStoreIndex.from_documents() 内部会:
# 1. 调用 text_embed_model 将每个文档转换为 256 维向量
# 2. 将向量存储到 Qdrant 的 chatpdf 集合中
# 3. 建立文本-向量的映射关系
print("开始向量嵌入...")
vector_index = VectorStoreIndex.from_documents(
documents,
storage_context=storage_context,
embed_model=text_embed_model,
)
print("向量嵌入完成,索引已创建!")
else:
# 分支 B: 已存在集合 - 直接加载现有索引
print("检测到已存在的集合,加载现有索引...")
vector_index = VectorStoreIndex.from_vector_store(
vector_store=vector_store,
embed_model=query_embed_model,
)
print("索引加载完成!")
return vector_index
# ============================================================
# 第五步: 创建向量索引
# ============================================================
index = create_or_get_index()
# ============================================================
# 第六步: 配置查询提示词
# ============================================================
# 通过精心设计的提示词,引导大模型:
# 1. 仅使用检索到的文档内容回答
# 2. 标注信息来源的页码
# 3. 以结构化的方式输出答案
custom_prompt = PromptTemplate(
"你是一个乐于助人的助手。使用以下内容作为你所学习的知识的来源。请仔细分析提供的文档内容,回答以下问题。避免使用你自己的知识。\n"
"文档内容:{context_str}\n"
"问题:{query_str}\n"
"请遵循以下要求:\n"
"1. 仅使用上述文档内容回答问题。\n"
"2. 如果信息分散在多个部分,请将相关信息整合在一起回答。\n"
"3. 即使信息出现在表格的不同行或列中,也要能够正确关联。\n"
"4. 如果上下文中没有直接相关信息,进行合理推算或估计,并说明是推算结果。\n"
"5. 以项目符号(bullet points)的形式列出陈述。\n"
"6. 每个陈述必须注明信息来源的页码,格式为 [页码]。页码信息位于每段文本的元数据中的 'page' 字段。\n"
"7. 如果一个陈述来自多个页面,请标注所有相关页码,如 [4][5]。\n"
)
# ============================================================
# 第七步: 创建查询引擎
# ============================================================
# 查询引擎是 RAG 系统的核心,负责:
# 1. 将用户问题转换为向量
# 2. 在 Qdrant 中检索相似文档
# 3. 使用重排序模型精排结果
# 4. 将检索结果和问题一起发送给 LLM
# 5. 生成最终答案
query_engine = index.as_query_engine(
llm=llm, # 使用 Deepseek 生成答案
embed_model=query_embed_model, # 使用查询嵌入模型
streaming=True, # 开启流式输出,实时返回答案
similarity_top_k=5, # 初步检索 5 个最相似的文档
text_qa_template=custom_prompt, # 使用自定义提示词
node_postprocessors=[jina_rerank], # 重排序: 5 个文档 → 精选 3 个
verbose=True, # 打印检索和生成的详细过程
)
# ============================================================
# 主函数: RAG 查询流程演示
# ============================================================
def main():
"""
RAG 查询的完整流程:
1. 用户提问
2. 问题向量化
3. 向量检索 (在 Qdrant 中找相似文档)
4. 重排序 (精选最相关的文档)
5. 生成答案 (LLM 基于检索结果回答)
6. 展示答案和引用来源
"""
# 步骤 1: 用户提问
query_str = "李军是谁?"
# 步骤 2-5: 查询引擎自动完成向量检索、重排序、生成答案
# 内部流程:
# 1. query_embed_model 将问题转为 256 维向量
# 2. Qdrant 检索出 5 个最相似的文档块
# 3. jina_rerank 重排序,精选出 3 个最相关的
# 4. 将 3 个文档块 + 问题 + 提示词发送给 Deepseek
# 5. Deepseek 生成答案并流式返回
response = query_engine.query(query_str)
# 步骤 6: 展示答案 (流式输出)
print("\n=== 模型回答 ===")
response_text = ""
for text in response.response_gen:
print(text, end="", flush=True)
response_text += text
print()
# 步骤 7: 展示引用来源 (用于验证答案的可靠性)
print("\n=== 参考文本片段 ===")
for i, node in enumerate(response.source_nodes, 1):
print(f"\n文本片段 {i}")
print("=" * 50)
print(f"相关度分数: {node.score:.3f}") # 重排序后的相关度分数
print(f"元数据信息: {node.metadata}") # 页码、位置等信息
print("-" * 50)
print("引用文本内容:")
# 只显示前 200 个字符,避免输出过长
print(node.text[:200] + "..." if len(node.text) > 200 else node.text)
print("=" * 50)
if __name__ == "__main__":
main()
关键代码解读
如果你觉得上面的完整代码太长,这里提取几个最关键的代码片段进行解读。
1. 文档分块与元数据提取
# 使用 Docling 智能分块
node_parser = DoclingNodeParser()
nodes = node_parser.get_nodes_from_documents(docs)
# 提取元数据用于引用溯源
for node in nodes:
metadata = {
"page": str(node.metadata["doc_items"][0]["prov"][0]["page_no"]), # 页码
"bbox": node.metadata["doc_items"][0]["prov"][0]["bbox"], # 位置
"headings": node.metadata.get("headings", []), # 标题
}
为什么重要:元数据是实现点击页码跳转的基础,没有 page 和 bbox 就无法溯源。
2. 向量嵌入与存储
# 创建向量索引(自动完成嵌入)
vector_index = VectorStoreIndex.from_documents(
documents,
storage_context=storage_context, # 指向 Qdrant
embed_model=text_embed_model, # 使用 Jina 嵌入模型
)
背后发生了什么:
- LlamaIndex 遍历所有 documents
- 调用
text_embed_model将每个文档转为 256 维向量 - 将向量和元数据一起存储到 Qdrant 的
chatpdf集合
3. 两阶段检索
query_engine = index.as_query_engine(
similarity_top_k=5, # 粗排:检索 5 个候选
node_postprocessors=[jina_rerank], # 精排:重排序后取 Top 3
)
检索流程:
用户问题 → 向量化 → Qdrant检索 Top5 → Jina重排序 Top3 → 发送给 LLM
4. 提示词工程
custom_prompt = PromptTemplate(
"你是一个乐于助人的助手。使用以下内容作为你所学习的知识的来源...\n"
"6. 每个陈述必须注明信息来源的页码,格式为 [页码]。\n"
)
为什么需要提示词:引导 LLM 输出结构化答案并标注页码,否则 LLM 可能不会主动标注来源。
运行与调试
首次运行:
python3 chatpdf.py
预期输出:
- 文档分块信息(53 个节点,平均 522 字符)
- 向量嵌入进度(可能需要 30-60 秒)
- 查询结果(带页码引用的答案)
- 参考文本片段(3 个最相关的片段)
常见问题:
| 问题 | 原因 | 解决方案 |
|---|---|---|
ConnectionError: Qdrant | Qdrant 未启动 | docker run -p 6333:6333 qdrant/qdrant |
AuthenticationError: Jina | API Key 错误 | 检查 .env 文件中的 JINA_API_KEY |
| 分块结果为空 | PDF 路径错误 | 确认 file_path 指向正确的 PDF 文件 |
| 检索结果不准确 | 参数未调优 | 尝试调整 similarity_top_k 和 top_n |
运行结果验证
可以通过三个维度验证系统的有效性:分块质量、检索准确性、溯源可靠性。
1. 溯源准确性验证
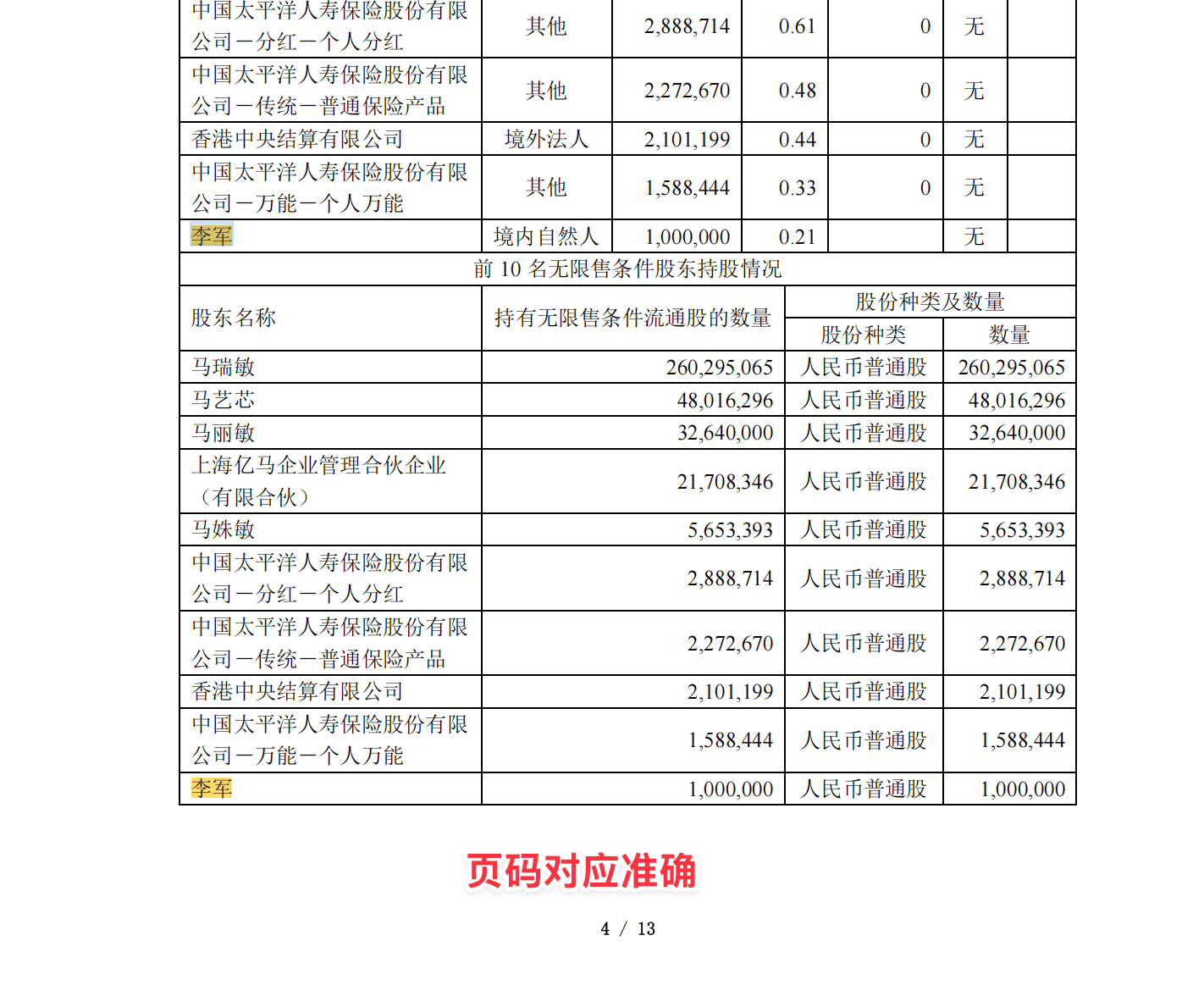
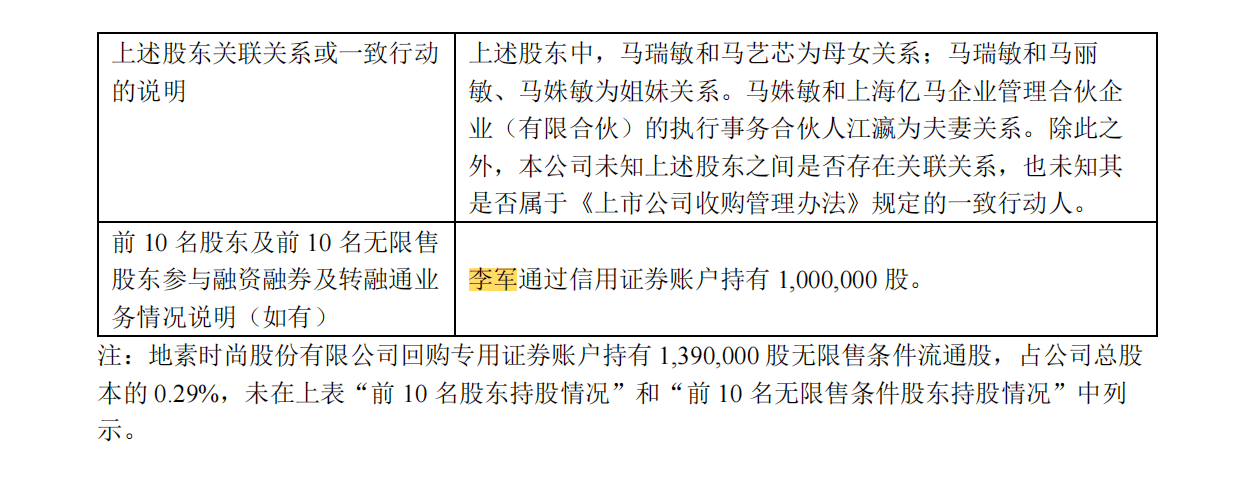
用户问题:"李军是谁?"
LLM 生成答案:
根据提供的文档内容,关于“李军”的信息如下:
* **身份**:李军被列为“境内自然人”。[4]
* **持股情况**:李军持有“人民币普通股 1,000,000 股”。[4]
* **持股方式说明**:李军通过信用证券账户持有这1,000,000股。[5]
PDF 原文对照:
分析结果:
页码精准:答案标注 [4][5],与 PDF 截图完全一致
数据准确:1,000,000 股的数字、"境内自然人"的分类、"信用证券账户"的持股方式,全部正确
元数据传递链路完整:
PDF解析 → 分块(保留page/bbox) → 向量存储 → 检索 → LLM → 带页码的答案
这验证了整个 RAG 管道的可靠性。
2. 分块效果验证
======================================================================
总节点数: 53 个
平均每块长度: 522 字符
最小块长度: 4 字符
最大块长度: 6099 字符
第一个节点详情:
文本长度: 9 字符
文本预览: 证券简称:地素时尚...
元数据: {'schema_name': 'docling_core.transforms.chunker.DocMeta', 'version': '1.0.0', 'doc_items': [{'self_ref': '#/texts/1', 'parent': {'$ref': '#/body'}, 'children': [], 'content_layer': 'body', 'label': 'text', 'prov': [{'page_no': 1, 'bbox': {'l': 174.02, 't': 763.1510439453125, 'r': 536.26, 'b': 752.5910439453125, 'coord_origin': 'BOTTOMLEFT'}, 'charspan': [0, 9]}]}], 'origin': {'mimetype': 'application/pdf', 'binary_hash': 17138581016858007644, 'filename': 'disu.pdf'}}
======================================================================
文档处理完成,共 53 个文档块
分析结果:
块大小适中:平均 522 字符,既保留语义完整性,又避免引入过多噪声
元数据完整:每个块都包含 page_no、bbox、headings,为引用溯源提供基础
块大小差异大:最小 4 字符,最大 6099 字符,说明 HierarchicalChunker 根据文档结构自适应分块。生产环境建议设置 max_chunk_size 限制上限。
3. 检索准确性验证
检索结果(重排序后的 Top 3):
文本片段 1
==================================================
相关度分数: 0.363
元数据信息: {'page': '4', 'bbox': {'l': 479.14, 't': 763.1510439453125, 'r': 526.42, 'b': 752.5910439453125, 'coord_origin': 'BOTTOMLEFT'}, 'headings': ['二、 股东信息']}
--------------------------------------------------
引用文本内容:
中国太平洋人寿保险股份有限 公司-传统-普通保险产品, 18,922 = 2,272,670. 中国太平洋人寿保险股份有限 公司-传统-普通保险产品, 报告期末表决权恢复的优先股股 东总数(如有) = 2,272,670. 中国太平洋人寿保险股份有限 公司-传统-普通保险产品, 报告期末表决权恢复的优先股股 东总数(如有) = 2,272,670. 中国太平洋人寿保险股份有限 公司-传统-普通保险...
==================================================
文本片段 2
==================================================
相关度分数: 0.358
元数据信息: {'page': '5', 'bbox': {'l': 89.73631286621094, 't': 766.5943450927734, 'r': 532.1719970703125, 'b': 639.1416931152344, 'coord_origin': 'BOTTOMLEFT'}, 'headings': ['二、 股东信息']}
--------------------------------------------------
引用文本内容:
上述股东关联关系或一致行动 的说明, 1 = 上述股东中,马瑞敏和马艺芯为母女关系;马瑞敏和马丽 敏、马姝敏为姐妹关系。马姝敏和上海亿马企业管理合伙企 业(有限合伙)的执行事务合伙人江瀛为夫妻关系。除此之 外,本公司未知上述股东之间是否存在关联关系,也未知其 是否属于《上市公司收购管理办法》规定的一致行动人。. 前 10 名股东及前 10 名无限售 股东参与融资融券及转融通业 务情况说明(如有),...
==================================================
文本片段 3
==================================================
相关度分数: 0.350
元数据信息: {'page': '4', 'bbox': {'l': 479.14, 't': 763.1510439453125, 'r': 526.42, 'b': 752.5910439453125, 'coord_origin': 'BOTTOMLEFT'}, 'headings': ['二、 股东信息']}
--------------------------------------------------
引用文本内容:
中国太平洋人寿保险股份有限 公司-分红-个人分红, 0 = 无. 中国太平洋人寿保险股份有限 公司-分红-个人分红, 0 = . 中国太平洋人寿保险股份有限 公司-传统-普通保险产品, 18,922 = 其他. 中国太平洋人寿保险股份有限 公司-传统-普通保险产品, 报告期末表决权恢复的优先股股 东总数(如有) = 2,272,670. 中国太平洋人寿保险股份有限 公司-传统-普通保险产品, 报告...
==================================================
分析结果:
分数接近:0.363、0.358、0.350 差距小,说明重排序模型有效识别了高度相关的片段
语义聚焦:3 个片段都来自"股东信息"章节,且都在第 4-5 页,说明检索定位精准
召回完整:片段 1 包含直接信息(李军持股),片段 2 提供上下文(股东关系),覆盖了问题的多个维度
重排序的价值:
初步向量检索返回可能的 5 个文档块,但重排序模型能识别出"李军"这个关键实体,将相关文档块排在前面。
关键成功因素总结
| 环节 | 关键设计 | 效果 |
|---|---|---|
| 分块 | HierarchicalChunker + 元数据保留 | 语义完整 + 可溯源 |
| 检索 | 两阶段检索(Top5 → Top3) | 召回率高 + 精度高 |
| 生成 | 提示词引导输出页码 | 结构化答案 + 可验证 |
运行结果分析
提示词工程
代码中的提示词模板引导 LLM:
- 仅使用检索到的文档内容回答
- 标注信息来源的页码(格式:
[页码]) - 以项目符号形式输出结构化答案
这是实现点击页码跳转 PDF 页面功能的基础。
生产级分块建议
示例代码使用 HierarchicalChunker 进行智能分块,适合快速原型。生产环境建议:
- 使用 Hybrid Chunker 配合 序列化
- 明确定义块大小(不同文档类型需要不同大小)
- 通过 A/B 测试找到最优块大小
扩展方向
本文演示了一个可运行的 ChatPDF 原型,要构建生产级应用还需要考虑:
性能优化
- 文档解析:CPU 解析速度慢,生产环境建议使用 GPU 加速或第三方解析服务
- 向量检索:调整批量嵌入参数(
embed_batch_size)、Qdrant 索引配置以提升吞吐量
功能扩展
- 跨文档检索:为文档添加唯一标识(
document_id),检索时通过元数据过滤实现多文档搜索 - 多模态支持:提取 PDF 图片后,可用多模态 LLM 生成描述再嵌入,或直接使用多模态嵌入模型
- 前端实现:前端拿到 LLM 输出的内容(包含引用页码
[4][5]),结合元数据中的page和bbox信息,使用pdf.js等库渲染 PDF 并实现引用段落高亮显示
总结
通过这篇文章,一起从零搭建了一个类 ChatPDF 的应用。回顾一下,你掌握了:
- RAG 系统的四大环节(解析 → 向量化 → 检索 → 生成)
- 如何根据成本和性能选择合适的技术栈
- 向量嵌入、分块策略、两阶段检索这些核心概念
最后说一句,做 RAG 应用最重要的是快速迭代:先把原型跑起来,再根据实际效果一点点优化。别想着一开始就做到完美,边做边改才是王道。
附件下载
本文使用的示例 PDF 文件(地素时尚季报)可以通过以下链接下载:





