AI 时代下,OCR 工具如何选择
最近看到一篇关于 OCR 工具选型的文章,内容很不错,索性翻译成了中文。
原文链接:https://dev.to/vtempest/pdf-gec
PDF 表格提取工具评测
随着 AI 技术的发展,PDF 解析领域涌现出大量新工具,与传统解析库各有所长。面对复杂 PDF 文档中的文本、表格和结构化数据提取需求,如何选择合适的工具成了一个关键问题。
本文对八款主流 PDF 处理方案进行评测,从能力、性能和适用场景等维度展开分析,希望能为你挑选合适的 OCR 工具提供一些参考。
总览
基于广泛的调研和性能基准测试,Docling 是处理复杂商业文档最稳健的框架,具备高文本提取精度、出色的表格结构保留能力,以及有效的文档布局分析,并且完全免费。
对于需要托管服务的企业环境,Reducto 提供卓越的准确性和企业级功能,起步价为每月 425 美元(太贵了)。
PyMuPDF 则在处理速度方面领先,比其他方案快 15-35 倍,适合大批量文本提取场景。
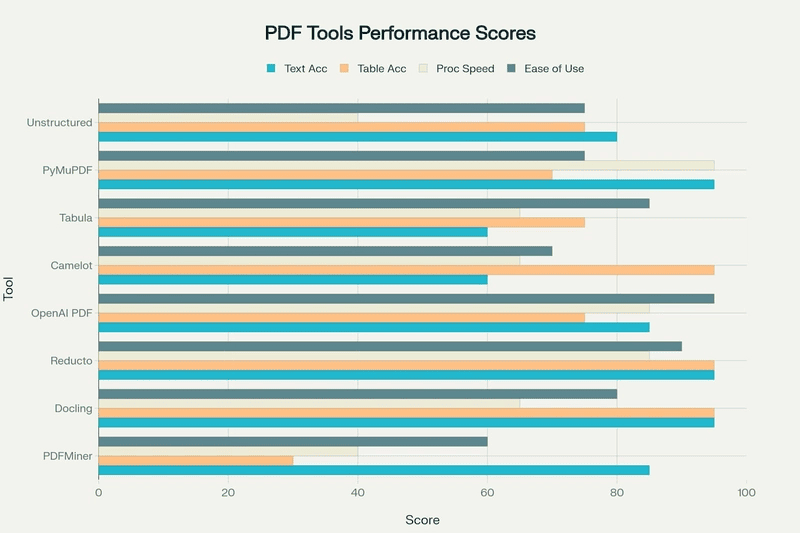
PDF 处理工具对比矩阵
各工具功能对比
| 功能 | PDFMiner | Docling | Reducto | OpenAI PDF | Camelot | Tabula | PyMuPDF | Unstructured |
|---|---|---|---|---|---|---|---|---|
| 文本提取精度 | 高 (85/100) | 极高 (95/100) | 极高 (95/100) | 高 (85/100) | 中 (60/100) | 中 (60/100) | 极高 (95/100) | 高 (80/100) |
| 表格提取质量 | 差 (30/100) | 优秀 (95/100) | 优秀 (95/100) | 良好 (75/100) | 优秀 (95/100) | 良好 (75/100) | 良好 (70/100) | 良好 (75/100) |
| 布局分析 | 基础 | 高级 | 高级 | 高级 | 仅表格 | 仅表格 | 基础 | 高级 |
| 处理速度 | 慢 | 中等 | 快 | 快 | 中等 | 中等 | 极快 | 慢 |
| OCR 支持 | 否 | 是 | 是 | 是 | 否 | 否 | 否 | 是 |
| 图表支持 | 否 | 是 | 是 | 是 | 否 | 否 | 否 | 有限 |
| 学习曲线 | 陡峭 | 中等 | 简单 | 极简单 | 中等 | 简单 | 中等 | 中等 |
| 编程语言 | Python | Python | API/SDK | API | Python | Java/Python | Python | Python |
价格对比
| 工具 | 起步价 | 企业版价格 | 计费模式 |
|---|---|---|---|
| PDFMiner | 免费 | 无 | 开源 |
| Docling | 免费 | 无 | 开源 (MIT) |
| Reducto | $425/月 | $1825+/月 | 按用量 API |
| OpenAI PDF | $0.001/token | 定制 | 按使用量付费 API |
| Camelot | 免费 | 无 | 开源 |
| Tabula | 免费 | 无 | 开源 |
| PyMuPDF | 免费 | 商业授权 | 双许可证 (AGPL/商业) |
| Unstructured | 免费 | 企业版方案 | 免费增值/SaaS |
性能基准测试
速度对比(每分钟处理页数)
- PyMuPDF:约 50-60 页/分钟
- Reducto:约 30-40 页/分钟
- OpenAI PDF:约 25-35 页/分钟
- Docling:约 20-25 页/分钟
- Camelot:约 15-20 页/分钟
- Tabula:约 15-20 页/分钟
- PDFMiner:约 5-10 页/分钟
- Unstructured:约 5-8 页/分钟
准确度排名(基于研究测试)
- 文本提取:Docling > PyMuPDF = Reducto > PDFMiner > OpenAI PDF > Unstructured > Camelot = Tabula
- 表格提取:Docling = Camelot = Reducto > OpenAI PDF = Tabula = Unstructured > PyMuPDF > PDFMiner
使用场景推荐
最适合简单文本提取
- PyMuPDF - 速度最快,准确度良好
- PDFMiner - 详细的布局信息,可定制
- Unstructured - 支持多种格式
最适合表格提取
- Camelot - 专业的表格提取,支持可视化调试
- Docling - 高级表格结构保留
- Reducto - 企业级表格处理
最适合复杂文档处理
- Docling - 高级布局分析,免费
- Reducto - 企业级功能,高准确度
- OpenAI PDF - AI 驱动的分析
最适合企业部署
- Reducto - 完整的企业功能,SLA 保障
- Docling - 开源,适合企业使用
- OpenAI PDF - 可扩展的 API
最适合预算有限的项目
- Docling - 高级功能,完全免费
- PyMuPDF - 处理速度快,开源免费
- Camelot - 优秀的表格提取,免费
技术要求
| 工具 | 依赖 | 部署方式 | 维护方式 |
|---|---|---|---|
| PDFMiner | Python 3.6+ | 本地/服务器 | 自行维护 |
| Docling | Python 3.8+, PyTorch | 本地/服务器/云 | 自行维护 |
| Reducto | API 密钥 | 云 | 托管服务 |
| OpenAI PDF | API 密钥 | 云 | 托管服务 |
| Camelot | Python, Ghostscript | 本地/服务器 | 自行维护 |
| Tabula | Java, Python 封装 | 本地/服务器 | 自行维护 |
| PyMuPDF | Python 3.7+ | 本地/服务器 | 自行维护 |
| Unstructured | Python 3.8+ | 本地/服务器/云 | 自行维护/托管 |
综合评分
| 工具 | 总分 | 最适合 |
|---|---|---|
| Docling | 89/100 | 复杂文档,免费方案 |
| Reducto | 85/100 | 企业级大批量处理 |
| PyMuPDF | 82/100 | 快速文本提取 |
| OpenAI PDF | 80/100 | AI 驱动的分析 |
| Unstructured | 77/100 | 多格式处理 |
| Camelot | 75/100 | 表格提取专家 |
| Tabula | 71/100 | 简单表格提取 |
| PDFMiner | 68/100 | 定制化文本提取需求 |
各工具详细分析
PDFMiner:基础库
PDFMiner 是最早的基于 Python 的 PDF 解析方案之一,专注于文本提取和布局分析。该库擅长提供文本定位、字体和布局结构的详细信息,适用于需要精确文档分析的应用。不过,它仅支持文本,且处理速度较慢(约每分钟 5-10 页),限制了其在现代文档处理需求中的适用性。
核心能力包括支持 PDF-1.7 规范、自动布局分析,以及转换为 HTML 和 XML 等多种输出格式。该工具的纯 Python 实现确保了广泛的兼容性,但相比包含编译组件的库牺牲了性能。
Docling:高级开源方案
由 IBM Research 开发的 Docling 已迅速成为领先的开源文档处理工具包。该系统集成了在近 81000 个人工标注页面上训练的高级计算机视觉模型,在识别文档元素方面达到了人类级别的准确度。最新的基准测试显示 Docling 在复杂文档处理方面的优势,表格提取的单元格准确率达 97.9%,密集段落的文本保真度达 100%。
Docling 的架构结合了 DocLayNet(用于布局分析)和 TableFormer(用于表格结构识别),实现了超越简单文本提取的全面文档理解。该工具包通过利用计算机视觉技术而非字符识别,处理文档的速度比传统 OCR 方法快 30 倍。
Reducto:企业级 API
Reducto 是专为企业文档处理工作流设计的高端商业方案。该平台已处理超过 2.5 亿份文档,最近获得了 2400 万美元的风险投资,表明市场对其的高度认可。Reducto 的 AI 驱动提取能力擅长处理复杂布局,包括表格、表单、图像和图表,准确度无与伦比。
该服务提供支持自定义 schema 的结构化 JSON 提取,使企业能够为文档处理管线定义特定的输出格式。企业功能包括 SSO 认证、零数据保留协议,以及面向安全敏感环境的 VPC 部署选项。
OpenAI PDF Upload:AI 驱动的文档分析
OpenAI 最近在其 API 中引入了直接 PDF 支持,这是 AI 驱动文档处理的重大进步。该系统同时处理每页的文本内容和视觉信息,能够全面分析包含图表、图形和复杂布局的文档。这种双输入方法使 GPT-4o 等视觉模型能够解读传统文本提取工具可能遗漏的视觉元素。
实现方式包括通过 Files API 上传文件或在 API 请求中直接使用 Base64 编码。不过,由于包含了每页的视觉数据,这种方式消耗的 token 量可能远超纯文本处理。
Camelot:表格提取专家
Camelot 已确立了其作为 PDF 表格提取领域首选开源方案的地位。该库利用计算机视觉算法检测表格结构,并提供丰富的配置参数用于微调提取结果。对比研究表明 Camelot 在基于网格线的表格提取场景中优于 Tabula。
该工具的优势在于可视化调试能力和对提取过程的精确控制,允许用户针对特定文档类型优化结果。不过,Camelot 专注于表格提取,限制了其在综合文档处理工作流中的实用性。
其他值得关注的工具
Tabula 是一款广泛使用的基础表格提取工具,对简单表格数据特别有效,但在处理复杂多栏布局时表现不佳。PyMuPDF 提供卓越的处理速度(每分钟 50-60 页)和高文本提取准确度,但缺乏高级表格处理能力。Unstructured 提供支持 OCR 的多格式文档处理,但处理速度较慢且结构解析存在不一致性。
PDF 处理工具的成本与功能复杂度对比(含流行度指标)
性能基准测试与准确度分析
对多种文档类别的全面评估揭示了工具之间的显著性能差异。在文本提取方面,PyMuPDF 和 pypdfium 通常优于其他方案,但所有解析器在处理科学论文和专利文档时都存在困难。基于深度学习的工具(如 Nougat)在处理高难度文档类别时表现更优。
表格检测能力因工具和文档类型而异。TableTransformer (TATR) 在金融、专利和科学文档中表现出色,而 Camelot 在政府招标文档中表现最佳。处理速度测量显示 PyMuPDF 的文本提取速度比 PDFMiner 快 15-35 倍,Reducto 和 OpenAI PDF 在基于 API 的方案中提供了具有竞争力的速度。
使用场景推荐与选型标准
学术和研究应用
Docling 为研究环境提供了准确度、高级功能和性价比的最佳平衡。其开源特性支持定制,同时提供企业级性能。
企业文档处理
Reducto 提供全面的企业功能和托管服务部署,适合需要可扩展、高准确度文档处理且运维开销最小的企业。Docling 则是偏好自托管方案的企业的优秀替代选择。
大批量文本提取
PyMuPDF 在优先考虑吞吐量而非高级布局分析的场景中提供无与伦比的处理速度,每分钟 50-60 页的处理速率大幅超越其他方案。
表格专项应用
Camelot 仍然是专业表格提取工作流的首选方案,为表格数据提供卓越的准确度和调试能力。
技术实施考量
各方案的部署复杂度差异显著。PDFMiner、Docling 和 Camelot 等开源工具需要本地安装和依赖管理,但能完全控制处理环境。Reducto 和 OpenAI PDF 等 API 方案消除了部署复杂度,但引入了对外部服务的依赖和持续的运营成本。
资源需求从 PDFMiner 等基础工具的最低要求,到 Docling 等高级方案的较高要求(需要 PyTorch 支持计算机视觉模型)不等。企业部署需考虑可扩展性、安全合规性以及与现有文档管理系统的集成等因素。
成本效益分析
经济方案涵盖从完全免费的开源方案到每月超过 1800 美元的高端企业服务。Docling 代表了极高的性价比,以零成本提供与商业方案相当的高级功能。Reducto 的高端定价反映了其企业定位和托管服务模式,而 OpenAI PDF 提供灵活的按使用量付费定价,适合工作量波动的场景。
对于预算有限的企业,将 Docling(用于复杂文档处理)和 PyMuPDF(用于高速文本提取)组合使用,可以在无许可成本的情况下获得全面的处理能力。
未来趋势与建议
PDF 处理领域正持续向 AI 原生方案演进,这些方案能够理解文档结构和上下文,而非仅仅提取文本。企业应优先选择具备高级布局分析和多模态处理能力的方案,以确保文档处理工作流的前瞻性。
Docling 是大多数使用场景的推荐方案,它将前沿技术与开源的可访问性相结合。对于特定需求,Reducto 满足需要托管服务的企业需求,而 Camelot 和 PyMuPDF 分别面向表格提取和高速处理的特定场景。
最终的选型决策取决于准确度要求、处理量、预算限制和技术基础设施能力之间的平衡。企业应使用具有代表性的文档样本评估工具,确保所选方案在大规模部署前满足特定的准确度和性能要求。





