没必要为向量数据库支付高昂的费用
几个月前因为错误的选择了嵌入模型的维度,导致多花了不少冤枉钱。最近也有朋友问我怎么选择嵌入模型的维度,看到网上有人甚至为一个大概只有 100 万向量的无服务器向量数据库每月支付超过 70 美元。随着数据的增长,在达到千万、上亿向量的时候,这个成本不敢想象。
向量数据库在推荐系统、语义搜索和问答系统中表现出色。但随着数据量不断增长,成本也会跟着水涨船高。如果我告诉你,对于向量数量只有几千万甚至上亿的数据集,你其实完全没必要为高级向量数据库花这个钱。
下面简单介绍几个概念:
- Matryoshka 俄罗斯套娃(MRL):一种模型训练技术,让模型能够把高维向量
嵌套在低维向量里面,这样你就可以把大的向量裁剪到 64 维甚至 32 维,而且性能损失不会太大。 - 在 Qdrant 创建向量集合时,只需要简单设置,就可以轻松处理数百万级别的向量,同时不会让内存占用急剧膨胀。
- 实际观测结果:500 万条 64 维向量只需约 0.5-1 GB 内存,可在月租 4 欧元的 VPS 上运行,而传统方案需要数十倍的资源和成本。
- 重排序与混合搜索:如何通过交叉编码器或基于关键词的兜底方案,来弥补量化带来的精度损失。
俄罗斯套娃表示学习(MRL)
在聊向量数据库或索引之前,我们先来搞清楚一个问题,为什么把向量压缩到 64 维后,检索性能还能保持得这么好?这背后的秘诀就是俄罗斯套娃表示学习(MRL)。
什么是 MRL?
MRL 的训练方式让嵌入模型能够把高维向量整齐地嵌套在低维子集里面,就像俄罗斯套娃一样。如果模型输出的是 1024 维向量,你可以直接截断成 768 维、256 维或者 64 维,而且每个子集依然是语义上有意义的表示。
这种方法已经被用在了一些顶尖的多语言嵌入模型上,比如 Jina Embeddings v3,以及 OpenAI 的部分最新嵌入模型。这类模型默认可能会输出 1024 维甚至更高维度的向量,但你完全可以根据模型的训练方式,只存储前 64 维、128 维或 256 维就够了。不过需要注意的是,不是所有嵌入模型都支持 MRL。
MRL 的优势
- 灵活性:不需要为不同的向量维度单独训练多个模型,一个模型就能输出多种维度级别的向量。
- 成本与速度:向量越小,检索时所需的存储空间和 CPU/GPU 开销就越少。如果你有数百万条向量,把维度从 1024 维压缩到 64 维,对云服务账单和查询延迟的影响可以说是颠覆性的。
- 平滑降级:得益于 MRL 的训练方式,性能下降的过程通常比暴力截断维度或随机投影要平缓得多。即使压缩到 64 维,语义信息的保留程度也会出乎意料地好。
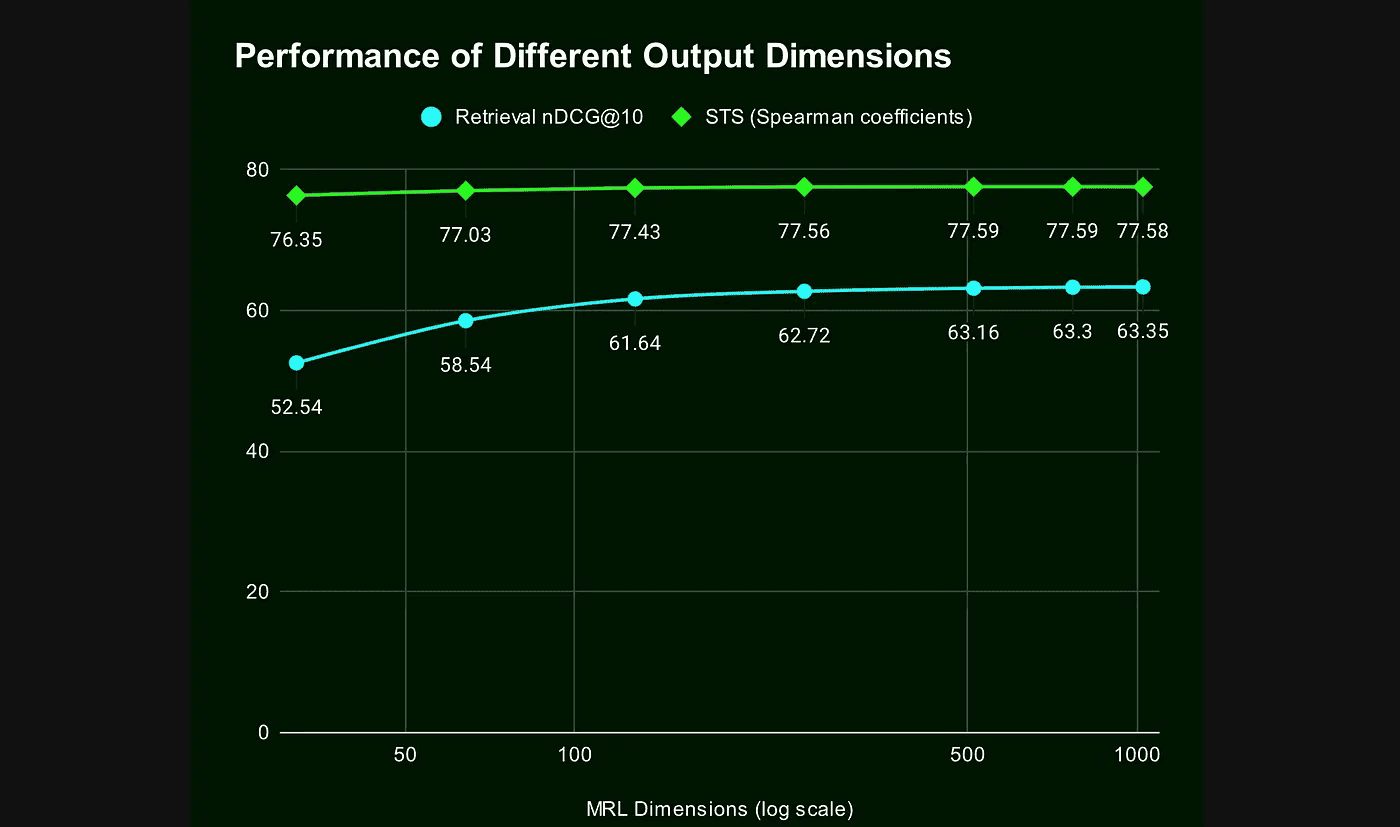
上图展示了 jina-embeddings-v3 在不同向量维度下的表现。随着维度增加,语义相似度和检索效果都会有所提升,但超过 256 维后提升已经不明显了。即使只用 64 维,性能也没有掉太多,检索效果只比最高维度低了大约 4~5 个点。
为什么需要重排序或混合检索
包括基于 MRL 的方法在内,各种压缩技术都可能略微降低召回率和精确率。不过在很多实际应用场景中,尤其是 RAG 工作流里,通常会采用两阶段流水线来解决这个问题:
- 检索阶段:用压缩或量化后的索引快速捞出
top-k候选结果。这个阶段的目标是快和省钱,即使牺牲一点精度也没关系。 - 重排序阶段:对
top-k结果做进一步的相关性精排,可以使用交叉编码器重排序模型(如 Cohere、Jina 或 OpenAI 的 Reranker)。这些模型计算开销更大,但精度更高,通过对候选结果和查询之间的关系进行深度分析来打分排序。
这套流水线可以有效弥补激进降维带来的召回损失。高效检索加上进阶重排序的组合,即使在复杂场景下也能保证最终输出的相关性。
尤其是结合 BM25(关键词)检索(也叫稀疏检索)和重排序一起用,即使对向量做了量化压缩,整体检索效果依然非常强大。
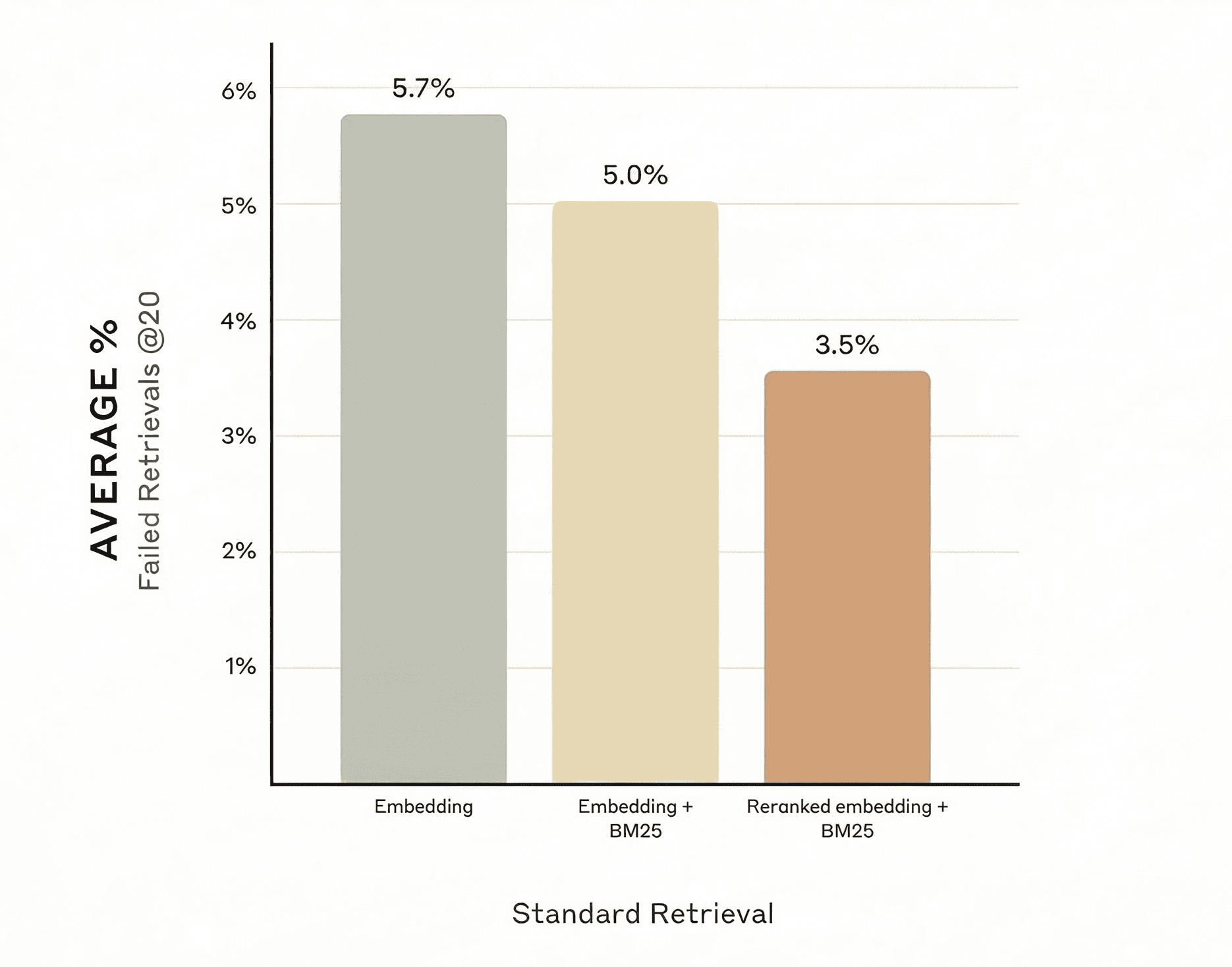
上图对比了不同检索策略的效果。只使用 Embedding 检索时,平均失败率约为 5.7%;在此基础上加入 BM25 关键词检索后,失败率下降到 5.0%。如果再加入 Reranker 进行重排序,失败率可以进一步降到 3.5%。整体来看,通过 Hybrid Search(Embedding + BM25)并结合 Rerank,可以明显提高检索的准确率。
使用 Qdrant 创建集合
既然你已经了解了如何通过 MRL 获得 64 维(甚至更低维度)的向量,接下来我们把它们存进一个低成本的向量集合里。创建集合时的设置如下:
- 完全禁用索引,延迟 HNSW 图构建,启用 int8 量化,向量数据和 HNSW 索引都启用磁盘存储,支持混合检索(密集+稀疏向量)。
注意:我们假设已经用一个支持 MRL 的模型生成了 500 万条向量,并将其压缩到了 64 维(当然也可以用其他 MRL 维度,比如 128 维或 256 维)。
安装依赖
pip install \
llama-index-core \
llama-index-embeddings-jinaai \
llama-index-postprocessor-jinaai-rerank \
llama-index-vector-stores-qdrant \
qdrant-client \
python-dotenv \
tiktoken
启动 Qdrant 服务实例
# 启动 Qdrant 服务
docker run -p 6333:6333 qdrant/qdrant
# 连接 Qdrant
client = QdrantClient(host="localhost", port=6333)
创建集合
client.create_collection(
collection_name=data.name,
# 混合检索配合 BM25 使用才开启
vectors_config={
"text-dense": models.VectorParams(
size=64, # 向量维度
distance=models.Distance.COSINE, # 距离度量方式
on_disk=True, # 是否将向量存储在磁盘上
)
},
sparse_vectors_config={
"text-sparse": models.SparseVectorParams(
index=models.SparseIndexParams(on_disk=True) # 是否将稀疏索引存储在磁盘上
)
},
quantization_config=models.ScalarQuantization(
scalar=models.ScalarQuantizationConfig(
type=models.ScalarType.INT8, # 量化类型
quantile=0.99, # 量化分位数,排除 1% 极端异常值,保持量化精度
always_ram=True, # 是否始终将量化后的向量存储在内存中
),
),
hnsw_config=models.HnswConfigDiff(
m=0,
# 数据嵌入完成后,将 hnsw_config: { "m": 0 } 还原为 16, on_disk: False
on_disk=True, # 是否将 HNSW 图数据存储在磁盘上,批量嵌入时开启,嵌入完成后关闭
),
# 创建集合时的优化器配置
optimizers_config=models.OptimizersConfigDiff(
indexing_threshold=0, # 批量嵌入过程中禁用索引更新, 上传完成之后还原成 20000
),
)
配置参数详解
上面的代码采用了两阶段配置策略,在批量导入和正常使用时使用不同的参数:
批量导入阶段(当前配置)
m=0: 完全禁用 HNSW 图构建,避免每次插入都更新索引,大幅提升导入速度indexing_threshold=0: 禁用自动索引触发,防止导入过程中的性能抖动on_disk=True: 将原始向量和 HNSW 图存储在磁盘,仅保留量化向量在内存(节省 75% 内存)always_ram=True: 量化向量始终保留在内存中,保证查询性能
导入完成后的配置恢复
数据导入完成后,执行以下操作恢复索引性能,否则查询延迟会非常高。
from qdrant_client import models
# 恢复 HNSW 索引配置
client.update_collection(
collection_name="your_collection",
hnsw_config=models.HnswConfigDiff(
m=16, # 恢复 HNSW 图构建,16 是推荐值(平衡精度和速度)
on_disk=False # 将 HNSW 图移到内存,加快查询速度
),
optimizers_config=models.OptimizersConfigDiff(
indexing_threshold=20000 # 恢复自动索引,每 2 万条向量触发一次优化
)
)
量化(Quantization)
量化是 Qdrant 的一个可选功能,可以让高维向量的存储和检索更加高效。通过把原始向量转换成新的表示形式,量化在压缩数据的同时,还能尽量保留向量之间原有的相对距离。
量化本身存在一定的取舍。一方面,量化可以大幅降低存储需求、加快检索速度,在那些对资源消耗非常敏感的大规模应用场景里,这个优势尤为突出。另一方面,量化会引入近似误差,可能导致检索质量略有下降。这种取舍的程度取决于量化方法及其参数,以及数据本身的特性。
下面简单介绍一下不同量化方式的差异,Qdrant 官方文档有更详细的说明。
标量量化(Scalar Quantization)
Qdrant 默认用32位浮点数来表示原始向量的每个分量。标量量化可以把位数压缩到8位,也就是说,Qdrant 会对每个向量分量做float32 -> uint8的转换。这样一来,存储一条向量所需的内存直接缩小到原来的四分之一。除了减少内存占用,标量量化还能加快检索速度。
标量量化的主要缺点是精度损失。float32 -> uint8的转换会引入误差,可能导致检索质量略有下降。不过这个误差通常可以忽略不计,而且对于高维向量来说影响往往更小。据 Qdrant 官方说,标量量化引入的误差通常不超过 1%。
二值量化(Binary Quantization)
二值量化是标量量化的一种极端形式,它把每个向量分量压缩成一个比特位,内存占用直接缩小到原来的三十二分之一。
这也是速度最快的量化方法,因为只需要几条 CPU 指令就能完成向量比较。
与原始向量相比,二值量化最高可以实现 40 倍的速度提升。
不过,二值量化只在高维向量上效果好,而且要求向量分量的分布接近中心对称。
维度较低或向量分量分布不符合要求的模型,可能需要额外做实验来找到最优的量化参数。
我们建议在开启重打分(rescoring)的情况下使用二值量化,这样只需付出很小的性能代价,就能显著提升检索质量。此外,还可以通过调整过采样倍数,在检索速度和检索质量之间灵活取舍。
乘积量化(Product Quantization)
乘积量化是一种通过把向量拆分成若干小块,再对每个块单独量化来压缩向量,从而减少内存占用的方法。
乘积量化的压缩比比标量量化更高,但也有一些取舍。乘积量化的距离计算对 SIMD 不友好,所以速度比标量量化慢。另外,乘积量化也存在精度损失,因此建议只在高维向量上使用。
如何选择合适的量化方法
下面是各种量化方法优缺点的简要对比表:
| Quantization method | Accuracy | Speed | Compression |
|---|---|---|---|
| Scalar | 0.99 | up to x2 | 4 |
| Product | 0.7 | 0.5 | up to 64 |
| Binary (1 bit) | 0.95* | up to x40 | 32 |
| Binary (1.5 bit) | 0.95** | up to x30 | 24 |
| Binary (2 bit) | 0.95*** | up to x20 | 16 |
*适用于支持高维向量的模型(约 1536 维以上)**适用于支持中维向量的模型(约 1024 到 1536 维)***适用于支持低维向量的模型(约 768 到 1024 维)
二值量化是速度最快、内存效率最高的方法,但要求向量分量的分布接近中心对称,建议只在经过验证的嵌入模型上使用。
如果打算在低维或中维向量(约 512 到 1024 维)上使用二值量化,建议同时启用 1.5 位或 2 位量化以及非对称量化功能。
标量量化是最通用的方法,在精度、速度和压缩比之间取得了不错的平衡,如果二值量化不适用,推荐作为默认的量化方案。
乘积量化可以提供更高的压缩比,但精度损失较大,速度也比标量量化慢。如果内存占用是首要考量、检索速度不是关键因素,可以考虑使用。
量化技巧
- 全部存在内存:默认原始向量和量化后的向量全部加载并保存在内存中,速度最快,但内存占有率很高。
- 原始向量存磁盘,量化向量存内存:这是一种混合模式,在速度和内存占用之间取得较好的平衡。如果你希望在保持检索速度的同时减少内存占用,推荐使用这种方案。上面的代码正是采用的这种优化方案。
- 全部存在磁盘:原始向量和量化后的向量全部存储在磁盘上,内存占用最小,但检索速度会相应下降。如果你的数据量很大,并且有较快的存储设备(比如 SSD 或 NVMe),推荐使用这种模式。
插入 500 万条 64 维向量
这一步就不做具体的展示了,下面有一段伪代码。
from llama_index.core import Document, VectorStoreIndex, StorageContext
from llama_index.vector_stores.qdrant import QdrantVectorStore
from llama_index.embeddings.jinaai import JinaEmbedding
import os
# LlamaIndex 包装 Qdrant(启用混合检索)
vector_store = QdrantVectorStore(
client=client,
collection_name="your_collection",
enable_hybrid=True, # 启用混合检索(密集向量 + 稀疏向量)
fastembed_sparse_model="Qdrant/bm25", # 使用 BM25 稀疏向量模型
batch_size=64, # 批量大小
)
storage_context = StorageContext.from_defaults(vector_store=vector_store)
# 配置 Jina 嵌入模型 (64 维 MRL)
embed_model = JinaEmbedding(
api_key=os.getenv("JINA_API_KEY"),
model="jina-embeddings-v3",
embed_batch_size=512,
dimensions=64,
task="retrieval.passage",
)
# 准备文档(实际应用中从数据库/文件分批加载,例如 5_000_000 条文档)
documents = load_documents_from_source() # 你的数据来源
# LlamaIndex 自动处理嵌入和批量插入(同时生成密集向量和稀疏向量)
index = VectorStoreIndex.from_documents(
documents,
storage_context=storage_context,
embed_model=embed_model,
show_progress=True, # 显示进度
)
实际效果
得益于 MRL,以及上面提到的各种优化措施,我们可以通过 Qdrant 的官方文章《Minimal RAM you need to serve a million vectors》来预估,存储和检索 500 万条 64 维向量只需要约 0.5-1 GB 的 RAM。这意味着它甚至可以轻松运行在一台月租 4 欧元、4GB RAM 的 netcup VPS 上,资源完全绰绰有余。

重排序与混合检索
即使用了 MRL、降维处理以及量化,你可能还是会担心召回率有所损失。但请记住:
- 在典型的 RAG 流水线里,你会先从向量索引里捞出 top-k 候选结果,再用交叉编码器(比如 Cohere、Jina 或 OpenAI 的模型)对结果做重排序。
- 你也可以把基于关键词或符号的检索和压缩后的向量结合起来用,也就是混合检索,用来覆盖一些边缘情况,这也是上面引入混合检索的原因。
由于最终结果很大程度上取决于重排序器或混合检索逻辑,只要你的嵌入模型支持 MRL,使用 64 维向量带来的那点召回率损失基本可以忽略不计。这样你就能两全其美,既有低成本的检索,又有高精度的最终答案。
最后
对于向量数量只有 500 万甚至几千万的场景,根本不需要为高级向量数据库套餐付费。借助俄罗斯套娃表示学习(MRL)把向量压缩到 64 维甚至更低,再配合向量数据库各种优化设置,你就可以把内存占用控制在合理范围内,同时保持不错的查询速度。
当然,更精细的方案(比如在内存索引里使用 1024 维向量)精度可能更高,但成本也会高得多,速度也更慢。在实际应用中,如果你在做 RAG 这类高级任务,都会用交叉编码器对 top-k 结果做重排序,这本身就能弥补量化带来的精度损失。这意味着你完全可以在不花大钱堆基础设施的情况下,依然提供高质量的语义搜索、推荐系统或问答服务。
别再为专用向量数据库多花冤枉钱了。把基于 MRL 的向量、量化、磁盘索引结合起来,你可以在一台低成本 VPS 上轻松扩展到数千万级向量,延迟依然可控,加上交叉编码器重排序或混合检索的加持,检索质量也丝毫不打折。
扩展阅读
Bulk Upload Vectors to a Qdrant Collection
Optimizing Memory for Bulk Uploads
Minimal RAM you need to serve a million vectors
Optimizing Qdrant Performance: Three Scenarios





