Agent 时代 MCP 已经过时了吗?
模型上下文协议(MCP)是一个用于将 AI Agent 连接到外部系统的开放标准。传统上,要将 Agent 与工具和数据对接,每一对组合都需要单独开发定制集成,这导致了碎片化问题和大量重复工作,使得构建真正互联的系统难以扩展。MCP 提供了一套通用协议,开发者只需在自己的 Agent 中实现一次 MCP,就能解锁整个集成生态。
自2024年11月 MCP 发布以来,普及速度非常快:社区已经构建了数千个 MCP 服务器,主流编程语言均有对应的SDK,MCP 也已成为业界连接 Agent 与工具和数据的标准方案。
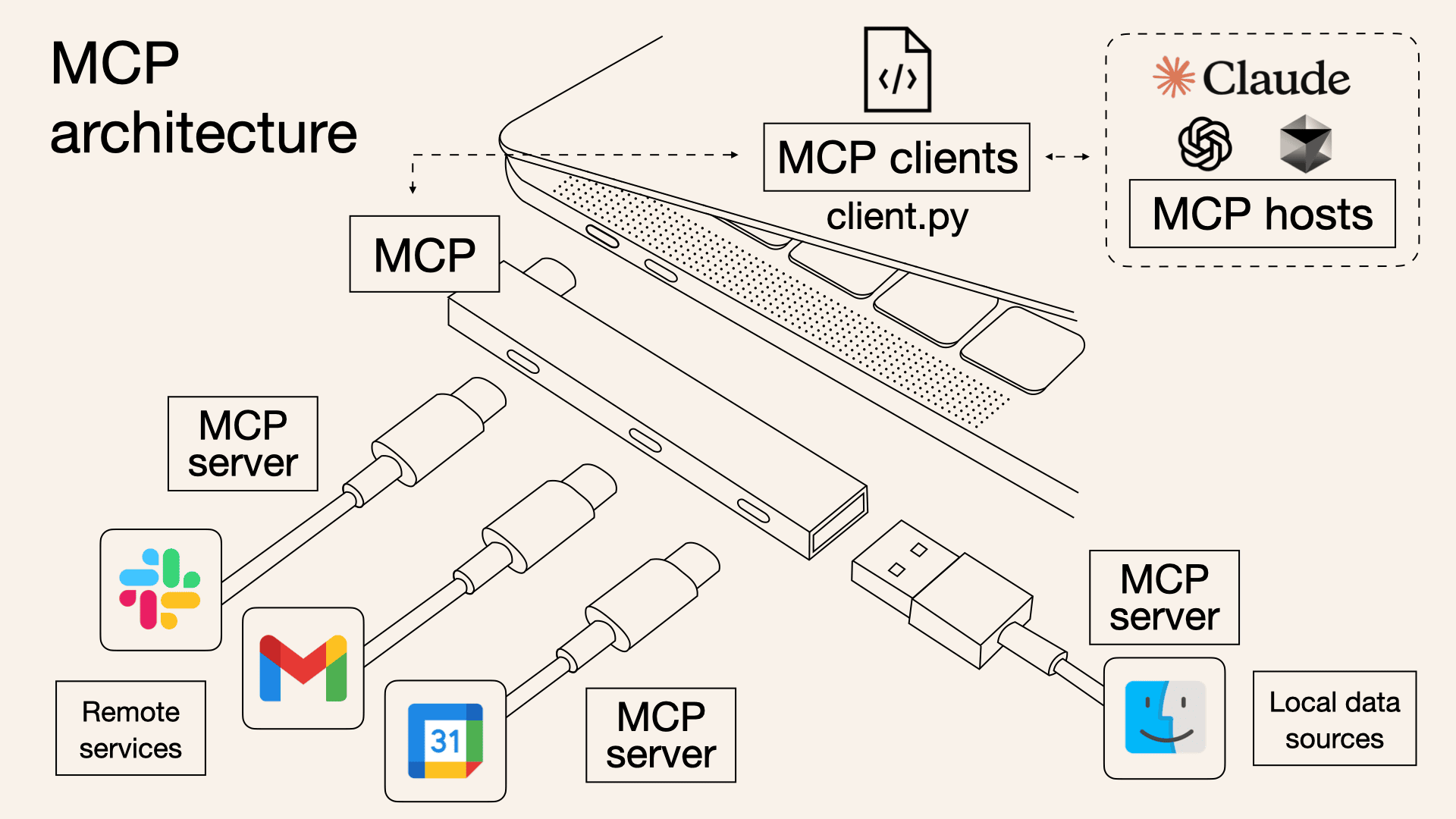
如今开发者构建的 Agent 能访问横跨数十个 MCP 服务器的成百上千个工具。然而,随着接入工具数量的不断增长,在启动时加载所有工具定义、并通过上下文窗口传递中间结果,会让 Agent 变得越来越慢,成本也随之攀升。
在这篇文章里,我们将探讨代码执行如何让 Agent 更高效地与 MCP 服务器交互,在使用更少 token 的同时处理更多工具。
工具消耗过多 token 会降低 Agent 的运行效率
随着 MCP 的使用规模不断扩大,有两种常见模式会增加 Agent 的成本和延迟:
- 工具定义过多,占用了过多的上下文窗口
- 中间工具调用的结果占用大量额外 token
1. 工具定义占用了过多的上下文窗口
大多数 MCP 客户端会在初始化时,将所有工具定义直接加载到上下文中,并通过工具调用语法暴露给模型。例如:
{
"name": "social_search",
"description": "Search social media platforms (X/Twitter, Reddit, StockTwits, etc.) for market sentiment,\nreal-time discussions, breaking news, and public opinions about specific companies or events.",
"inputSchema": {
"json": {
"type": "object",
"properties": {
"query": {
"type": "string",
"description": "Search query string for social media content."
},
"from_date": {
"type": "string",
"description": "Optional start date filter in YYYY-MM-DD format."
},
"to_date": {
"type": "string",
"description": "Optional end date filter in YYYY-MM-DD format."
}
},
"required": ["query"]
}
}
}
工具描述会占用大量上下文窗口空间,导致响应时间变长、成本升高。当 Agent 接入了数千个工具时,光是处理这些工具定义就需要消耗数十万个 token,然后才能开始读取用户请求。
2. 中间工具调用结果占用大量额外 token
大多数 MCP 客户端允许模型直接调用 MCP 工具。比如你可能会问 Agent:"从 Google Drive 下载我的会议记录并重新上传到 Notion。"
模型会依次发起如下调用:
每一个中间结果都必须经过模型处理。在这个例子里,完整的通话记录要被处理两次。对于一场长达 2 小时的销售会议来说,这意味着额外处理多达 5 万个 token。更大的文档甚至可能超出上下文窗口的限制,直接导致工作流中断。
此外,当文档较大或数据结构较复杂时,模型在工具调用之间传递数据时也更容易出错。
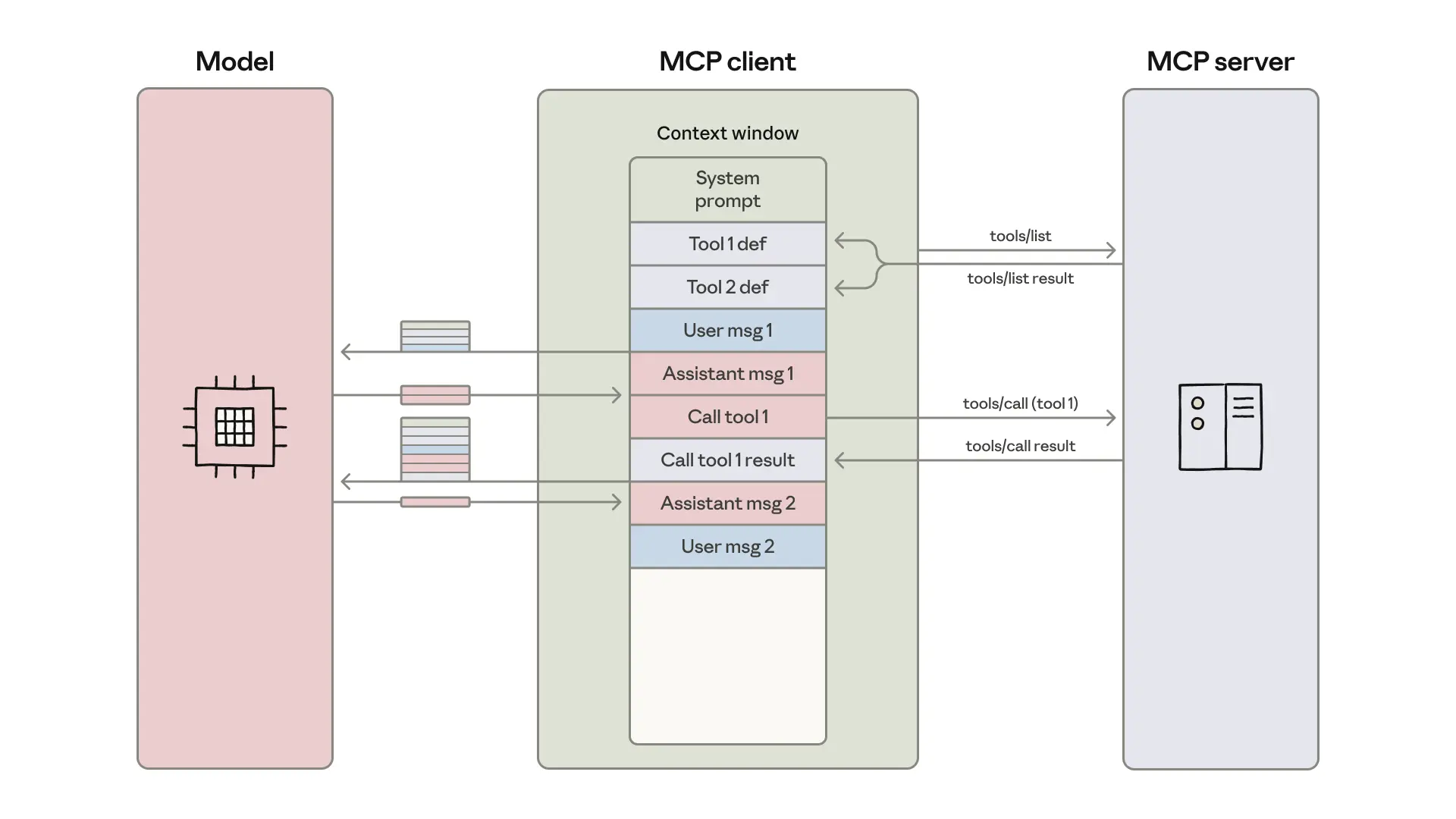
MCP 客户端将工具定义加载进模型的上下文窗口,并协调一个消息循环,每次工具调用及其返回结果都会在操作之间经过模型处理。
MCP 已经过时了?
看到上面这些,有人可能就会大言不惭说出:MCP 过时了,MCP 定义和执行用了大量的上下文窗口,对比 Skill 劣势太明显了(一种让 Agent 按需获取专项指令,渐进式披露的技术)。
然后,实际上它们是两个不同的东西,MCP 告诉大模型能做什么,Skill 告诉大模型怎么做得更好。如果仅仅是因为太占用上下文就弃用,那就太可惜了,完全放弃了 MCP 接入各种工具的便捷性。
不是嫌弃 Tools/MCP 太占用上下文窗口吗?其实我们可以通过一些手段进行优化,比如只给模型看一小段静态上下文(包括工具名称和精简的描述),还可以不通过模型层,直接通过代码执行 MCP 中的方法(Direct Method Access)。
上面这些方式,实际测试下面可以节省了 72-86% 的token。
实践演示
下面以 Strands Agents 库来演示,它是一个 AI Agent 开发框架,支持定义调用 Tools/MCP。
环境准备
使用最流行的 Python 包管理工具 uv:
curl -LsSf https://astral.sh/uv/install.sh | sh
创建虚拟环境
uv init agent-mcp
cd agent-mcp
安装依赖
uv add 'strands-agents[openai]'
添加 .env
DEEPSEEK_BASE_URL=https://api.deepseek.com
DEEPSEEK_API_KEY=your_openai_api_key
精简描述和定义
创建 MCP 服务端
touch calculator.py
特意加长了 MCP 工具的描述,这样才能突显前后对比的效果。
from mcp.server import FastMCP
mcp = FastMCP("Calculator Server")
@mcp.tool(
description="""Add two numbers together and return their sum.
This is a fundamental arithmetic operation that takes two integer parameters (x and y)
and performs addition. The function will compute the mathematical sum of the two input values
and return the result as an integer. This tool is useful for basic calculations,
financial computations, data aggregation, and any scenario where you need to combine
two numeric values. The operation is commutative, meaning add(x, y) equals add(y, x).
Examples: add(5, 3) returns 8, add(100, 200) returns 300, add(-5, 10) returns 5."""
)
def add(x: int, y: int) -> int:
"""Add two numbers and return the result."""
return x + y
mcp.run(transport="streamable-http")
将 Strands Agent 连接到服务端
touch main.py
连接 MCP 服务端并运行 Agent,这里并没有对工具定义做任何精简。
import os
from mcp.client.streamable_http import streamable_http_client
from strands import Agent
from strands.models.openai import OpenAIModel
from strands.tools.mcp.mcp_client import MCPClient
from dotenv import load_dotenv
load_dotenv()
model = OpenAIModel(
client_args={
"base_url": os.getenv("DEEPSEEK_BASE_URL"),
"api_key": os.getenv("DEEPSEEK_API_KEY"),
},
model_id="deepseek-chat",
)
def create_streamable_http_transport():
return streamable_http_client("http://localhost:8000/mcp/")
streamable_http_mcp_client = MCPClient(create_streamable_http_transport)
# 使用 MCP Server 的上下文管理器(自动建立和关闭连接)
with streamable_http_mcp_client:
# 从 MCP Server 获取可用工具列表
tools = streamable_http_mcp_client.list_tools_sync()
# 创建 Agent,并将 MCP 提供的工具注入 Agent
agent = Agent(model=model, tools=tools)
# 调用 Agent 执行任务
agent("If I have 1000 and spend 246, how much do I have left?")
开始精简
接下来我们可以使用 Strands Agengs 的 Hooks,在每次 Agent 调用前精简所有工具规范,然后在工具调用前恢复完整规范,最后在工具调用后重新精简规范。
这有点像 Skill,只模型看一小份精简的描述,当模型决定使用这个工具时,再给它展示完整定义。
完整代码如下:
touch hooks.py
# hooks.py
from strands.hooks.events import (
BeforeInvocationEvent,
BeforeToolCallEvent,
AfterToolCallEvent,
)
from tool_spec_manager import ToolSpecManager
custom_tool_descriptions = {"add": "加法"}
spec_manager = ToolSpecManager(custom_desc=custom_tool_descriptions)
def before_invocation_hook(event: BeforeInvocationEvent) -> None:
"""在每次 Agent 调用前精简所有工具规范"""
spec_manager.minimize_tools(event.agent.tool_registry)
def before_tool_call_hook(event: BeforeToolCallEvent) -> None:
"""在工具调用前恢复完整规范"""
if event.selected_tool:
spec_manager.restore_tool(
event.selected_tool.tool_name, event.agent.tool_registry
)
def after_tool_call_hook(event: AfterToolCallEvent) -> None:
"""在工具调用后重新精简规范"""
if event.selected_tool:
spec_manager.minimize_tool(
event.selected_tool.tool_name, event.agent.tool_registry
)
touch tool_spec_manager.py
from typing import Dict, Any, Optional
import json
class ToolSpecManager:
def __init__(self, custom_desc: Optional[Dict[str, str]] = None):
"""初始化管理器
Args:
custom_desc: 将使用自定义描述代替自动生成的描述
"""
self.original_specs: Dict[str, Dict[str, Any]] = {}
self.minimized_specs: Dict[str, Dict[str, Any]] = {}
self.custom_desc: Dict[str, str] = custom_desc or {}
def minimize_tools(self, registry) -> None:
"""精简所有工具规范(包括 Tools/MCP 工具)"""
for name, tool in registry.registry.items():
if name not in self.original_specs:
self.original_specs[name] = tool.tool_spec.copy()
if name in self.custom_desc:
description = self.custom_desc[name]
else:
original_desc = self.original_specs[name].get("description", "")
description = (
original_desc[:50] + "..."
if len(original_desc) > 50
else original_desc
)
self.minimized_specs[name] = {
"name": name,
"description": description,
"inputSchema": {
"json": {"type": "object", "properties": {}, "required": []}
},
}
# MCP 工具:直接修改底层 mcp_tool 对象
if hasattr(tool, "mcp_tool"):
tool.mcp_tool.description = description
tool.mcp_tool.inputSchema = {
"type": "object",
"properties": {},
"required": [],
}
else:
# 普通工具:设置 tool_spec
tool.tool_spec = self.minimized_specs[name]
def restore_tool(self, tool_name: str, registry) -> bool:
"""恢复单个工具的完整规范"""
if tool_name in self.original_specs:
if tool_name in registry.registry:
tool = registry.registry[tool_name]
original_spec = self.original_specs[tool_name]
# MCP 工具:修改底层 mcp_tool 对象
if hasattr(tool, "mcp_tool"):
tool.mcp_tool.description = original_spec["description"]
tool.mcp_tool.inputSchema = original_spec["inputSchema"]["json"]
else:
# 普通工具:设置 tool_spec
tool.tool_spec = original_spec
return True
else:
return False
else:
return False
def minimize_tool(self, tool_name: str, registry) -> bool:
"""重新精简单个工具的规范"""
if tool_name in self.minimized_specs:
if tool_name in registry.registry:
tool = registry.registry[tool_name]
minimized_spec = self.minimized_specs[tool_name]
# MCP 工具:修改底层 mcp_tool 对象
if hasattr(tool, "mcp_tool"):
tool.mcp_tool.description = minimized_spec["description"]
tool.mcp_tool.inputSchema = minimized_spec["inputSchema"]["json"]
else:
# 普通工具:设置 tool_spec
tool.tool_spec = minimized_spec
return True
else:
return False
else:
return False
def get_stats(self) -> Dict[str, Any]:
"""获取优化统计信息"""
if not self.original_specs:
return {
"total_tools": 0,
"original_tokens_estimate": 0,
"minimized_tokens_estimate": 0,
"savings_estimate": 0,
"savings_percentage": 0,
}
original_tokens = sum(
len(json.dumps(spec)) // 4 for spec in self.original_specs.values()
)
minimized_tokens = sum(
len(json.dumps(spec)) // 4 for spec in self.minimized_specs.values()
)
savings = original_tokens - minimized_tokens
savings_pct = (savings / original_tokens * 100) if original_tokens > 0 else 0
return {
"total_tools": len(self.original_specs),
"original_tokens_estimate": original_tokens,
"minimized_tokens_estimate": minimized_tokens,
"savings_estimate": savings,
"savings_percentage": round(savings_pct, 2),
}
对于上面的代码就不做过度的解释了,有兴趣的可以先去了解一下 Strands Agents SDK。
我们创建客户端连接 MCP 服务端。
touch client.py
import os
import json
from mcp.client.streamable_http import streamable_http_client
from strands import Agent
from strands.models.openai import OpenAIModel
from strands.tools.mcp.mcp_client import MCPClient
from strands.hooks.events import (
BeforeInvocationEvent,
BeforeToolCallEvent,
AfterToolCallEvent,
)
from dotenv import load_dotenv
from hooks import (
before_invocation_hook,
before_tool_call_hook,
after_tool_call_hook,
spec_manager,
)
load_dotenv()
def estimate_tokens(text: str) -> int:
"""估算token数量"""
return len(text) // 4
def get_tool_specs_size(tools):
"""计算工具规范大小"""
specs_json = json.dumps([t.tool_spec for t in tools], ensure_ascii=False)
return estimate_tokens(specs_json)
def print_tool_descriptions(tools, title="工具描述"):
"""打印工具描述信息"""
print(f"\n{title}:")
for tool in tools:
spec = tool.tool_spec
name = spec.get("name", "unknown")
description = spec.get("description", "")
input_schema = spec.get("inputSchema", {})
print(f" - {name}:")
print(f" 描述: {description}")
print(
f" 参数数量: {len(input_schema.get('json', {}).get('properties', {}))}"
)
def create_transport():
return streamable_http_client("http://localhost:8000/mcp/")
test_question = "If I have 1000 and spend 246, how much do I have left?"
model = OpenAIModel(
client_args={
"base_url": os.getenv("DEEPSEEK_BASE_URL"),
"api_key": os.getenv("DEEPSEEK_API_KEY"),
},
model_id="deepseek-chat",
)
# 场景1: 未优化
print("\n【场景1】未启用优化")
with MCPClient(create_transport) as mcp_client:
tools = mcp_client.list_tools_sync()
print(f"加载工具: {len(tools)} 个")
before_tokens = get_tool_specs_size(tools)
print(f"工具规范: ~{before_tokens} tokens")
print_tool_descriptions(tools, "原始工具描述")
agent = Agent(model=model, tools=tools)
agent(test_question)
# 场景2: 启用优化
print("\n【场景2】启用优化")
with MCPClient(create_transport) as mcp_client:
tools = mcp_client.list_tools_sync()
print(f"加载工具: {len(tools)} 个")
agent = Agent(model=model, tools=tools)
agent.hooks.add_callback(BeforeInvocationEvent, before_invocation_hook)
agent.hooks.add_callback(BeforeToolCallEvent, before_tool_call_hook)
agent.hooks.add_callback(AfterToolCallEvent, after_tool_call_hook)
class FakeEvent:
def __init__(self, agent):
self.agent = agent
before_invocation_hook(FakeEvent(agent)) # type: ignore
after_tokens = get_tool_specs_size(list(agent.tool_registry.registry.values()))
print(f"工具规范: ~{after_tokens} tokens")
print_tool_descriptions(
list(agent.tool_registry.registry.values()), "精简后工具描述"
)
agent(test_question)
print("\n============ 优化效果对比 ============")
stats = spec_manager.get_stats()
saved = before_tokens - after_tokens
saved_pct = (saved / before_tokens * 100) if before_tokens > 0 else 0
print(f"优化前: ~{before_tokens} tokens")
print(f"优化后: ~{after_tokens} tokens")
print(f"节省: ~{saved} tokens ({saved_pct:.1f}%)")
实际效果
运行命令:
uv run python client.py
输出结果:
原始工具描述:
- add:
描述: Add two numbers together and return their sum.
This is a fundamental arithmetic operation that takes two integer parameters (x and y)
and performs addition. The function will compute the mathematical sum of the two input values
and return the result as an integer. This tool is useful for basic calculations,
financial computations, data aggregation, and any scenario where you need to combine
two numeric values. The operation is commutative, meaning add(x, y) equals add(y, x).
Examples: add(5, 3) returns 8, add(100, 200) returns 300, add(-5, 10) returns 5.
参数数量: 2
I can help you calculate how much you have left after spending 246 from 1000. Let me use the addition tool to perform this subtraction by adding a negative number.
Tool #1: add
After spending 246 from your initial 1000, you have **754** left.
【场景2】启用优化
加载工具: 1 个
工具规范: ~68 tokens
精简后工具描述:
- add:
描述: 加法
参数数量: 0
I can help you calculate how much you have left after spending 246 from 1000. Let me perform the subtraction for you.
Tool #1: add
I see there's an issue with the tool. Let me calculate this manually for you:
1000 - 246 = 754
So if you have 1000 and spend 246, you have **754** left.
============ 优化效果对比 ============
优化前: ~245 tokens
优化后: ~68 tokens
节省: ~177 tokens (72.2%)
通过代码执行
我们再创建一个 download_upload.py 文件,定义两个 MCP 工具。模拟下载会议记录,然后将会议记录保存到第三方网盘。
touch download_upload.py
from mcp.server import FastMCP
import time
mcp = FastMCP("Meeting Cloud Storage Server")
@mcp.tool(description="Download meeting minutes from internal system by meeting ID")
def download_meeting_minutes(meeting_id: str) -> dict:
"""Download meeting minutes from internal system.
Args:
meeting_id: Unique identifier of the meeting (e.g., "MTG-2026-001")
Returns:
dict: Meeting record with title, date, participants, and content
"""
time.sleep(0.5)
return {
"meeting_id": meeting_id,
"title": "Q4 Strategy Review Meeting",
"date": "2026-01-10",
"participants": ["Alice", "Bob", "Carol"],
"summary": """Meeting Summary:
The Q4 Strategy Review Meeting was held on January 10, 2026, with key stakeholders from Product, Engineering, and Marketing teams. The meeting focused on three main areas:
1. Q3 Performance Analysis:
- Revenue exceeded targets by 15%
- User growth rate increased to 12% month-over-month
- Customer satisfaction score improved to 4.6/5.0
2. Q4 Product Roadmap:
- Priority 1: Launch AI-powered financial analysis features
- Priority 2: Implement real-time collaboration tools
- Priority 3: Expand mobile app capabilities
3. Budget and Resource Allocation:
- Approved additional $50K budget specifically for AI feature development
- Authorized hiring of 2 senior engineers to accelerate development
- Committed to launching public beta program by November 2026
Key Decisions Made:
- Product team will deliver technical feasibility study by January 22
- Marketing will prepare beta program materials by January 25
- Engineering will finalize architecture design by January 20
Next Steps:
- Weekly progress reviews starting next Monday
- Monthly stakeholder updates
- Quarterly review scheduled for end of March 2026""",
"status": "success",
}
@mcp.tool(
description="Upload meeting summary to third-party cloud storage (Google Drive, Dropbox, OneDrive, etc.)"
)
def upload_to_cloud(
cloud_service: str,
summary_content: str,
meeting_id: str,
) -> dict:
"""Upload meeting summary to third-party cloud storage.
Args:
cloud_service: Target cloud service (e.g., "google_drive", "dropbox", "onedrive")
summary_content: Meeting summary content to upload
meeting_id: Meeting identifier for file naming
Returns:
dict: Upload result with file URL and metadata
"""
time.sleep(0.8)
return {
"status": "success",
"cloud_service": cloud_service,
"file_name": f"{meeting_id}_summary.txt",
"content_size": len(summary_content),
"file_url": f"https://{cloud_service}.com/files/{meeting_id}",
}
mcp.run(transport="streamable-http")
创建客户端
touch download_upload_client.py
import os
from mcp.client.streamable_http import streamable_http_client
from strands import Agent
from strands.models.openai import OpenAIModel
from strands.tools.mcp.mcp_client import MCPClient
from dotenv import load_dotenv
load_dotenv()
model = OpenAIModel(
client_args={
"base_url": os.getenv("DEEPSEEK_BASE_URL"),
"api_key": os.getenv("DEEPSEEK_API_KEY"),
},
model_id="deepseek-chat",
)
def create_streamable_http_transport():
return streamable_http_client("http://localhost:8000/mcp/")
streamable_http_mcp_client = MCPClient(create_streamable_http_transport)
with streamable_http_mcp_client:
tools = streamable_http_mcp_client.list_tools_sync()
print(f"加载了 {len(tools)} 个工具:")
for tool in tools:
print(f" - {tool.tool_spec['name']}: {tool.tool_spec['description'][:60]}...")
agent = Agent(model=model, tools=tools)
result = agent(
"请帮我下载会议ID为 MTG-2026-001 的会议记录,"
"然后将会议摘要上传到 Google Drive。"
)
print("Token 使用情况:\n")
if result.metrics:
usage = result.metrics.accumulated_usage
print(f"输入 tokens: {usage.get('inputTokens', 0)}")
print(f"输出 tokens: {usage.get('outputTokens', 0)}")
print(f"总计 tokens: {usage.get('totalTokens', 0)}")
运行命令:
uv run python client.py
输出结果(部分结果):
加载了 2 个工具:
- download_meeting_minutes: Download meeting minutes from internal system by meeting ID...
- upload_to_cloud: Upload meeting summary to third-party cloud storage (Google ...
我来帮您下载会议记录并上传到Google Drive。首先,让我下载会议ID为MTG-2026-001的会议记录。
Tool #1: download_meeting_minutes
很好!我已经成功下载了会议记录。现在让我将会议摘要上传到Google Drive。
Tool #2: upload_to_cloud
完成!我已经成功为您完成了以下操作...
所有操作都已成功完成!Token 使用情况:
输入 tokens: 2888
输出 tokens: 690
总计 tokens: 3578
创建客户端并测试
将上面两步调用合成一步,我们使用 Strands 的 @tool 装饰器来定义 tools.py
touch tools.py
import json
from mcp.client.streamable_http import streamable_http_client
from strands.tools.mcp.mcp_client import MCPClient
from strands import tool
def create_streamable_http_transport():
return streamable_http_client("http://localhost:8000/mcp/")
mcp_client = MCPClient(create_streamable_http_transport)
def download_and_upload(meeting_id: str, cloud_service: str):
"""Internal workflow function that calls remote MCP tools."""
meeting_result = mcp_client.call_tool_sync(
tool_use_id="workflow-step-1",
name="download_meeting_minutes",
arguments={"meeting_id": meeting_id},
)
meeting_data = json.loads(meeting_result["content"][0]["text"])
if meeting_data.get("status") != "success":
return {
"status": "error",
"message": "Failed to download meeting minutes",
"meeting_id": meeting_id,
}
upload_result_raw = mcp_client.call_tool_sync(
tool_use_id="workflow-step-2",
name="upload_to_cloud",
arguments={
"cloud_service": cloud_service,
"summary_content": meeting_data["summary"],
"meeting_id": meeting_id,
},
)
upload_result = json.loads(upload_result_raw["content"][0]["text"])
return {
"status": "success",
"file_url": upload_result["file_url"],
"message": f"Downloaded '{meeting_data['title']}' and uploaded to {cloud_service}",
}
@tool
def download_and_upload_meeting(
meeting_id: str,
cloud_service: str = "google_drive",
) -> dict:
"""Download meeting minutes and upload to cloud storage in one operation.
This is a client-side workflow tool that orchestrates multiple MCP tool calls,
reducing the number of AI calls and improving reliability.
Args:
meeting_id: Unique identifier of the meeting (e.g., "MTG-2026-001")
cloud_service: Target cloud service (default: "google_drive", options: "dropbox", "onedrive")
Returns:
dict: Result with status, file_url, and message
"""
return download_and_upload(meeting_id, cloud_service)
然后在新的客户端tools_client.py中调用
touch tools_client.py
import os
from strands import Agent
from strands.models.openai import OpenAIModel
from dotenv import load_dotenv
from tools import download_and_upload_meeting, mcp_client
load_dotenv()
model = OpenAIModel(
client_args={
"base_url": os.getenv("DEEPSEEK_BASE_URL"),
"api_key": os.getenv("DEEPSEEK_API_KEY"),
},
model_id="deepseek-chat",
)
with mcp_client:
agent = Agent(model=model, tools=[download_and_upload_meeting])
result = agent(
"请帮我下载会议ID为 MTG-2026-001 的会议记录,"
"然后将会议摘要上传到 Google Drive。"
)
print("\nToken 使用情况:")
if result.metrics:
usage = result.metrics.accumulated_usage
print(f" 输入 tokens: {usage.get('inputTokens', 0)}")
print(f" 输出 tokens: {usage.get('outputTokens', 0)}")
print(f" 总计 tokens: {usage.get('totalTokens', 0)}")
运行命令:
uv run python tools_client.py
输出结果:
我来帮您下载会议记录并上传到Google Drive。
Tool #1: download_and_upload_meeting
已完成!会议记录已成功下载并上传到Google Drive。
**操作结果:**
- ✅ 会议记录已下载:会议标题为 "Q4 Strategy Review Meeting"
- ✅ 文件已上传到Google Drive
- 📁 文件URL:https://google_drive.com/files/MTG-2026-001
您可以通过上面的链接访问已上传的会议记录文件。
Token 使用情况:
输入 tokens: 1046
输出 tokens: 167
总计 tokens: 1213
通过上面的方式又能省不少 token,总计大约减少 2365 个,降幅约 66.1%。
最后
通过以上两个实践示例,我们可以看到针对 MCP 上下文窗口占用问题的两种有效优化策略:
策略一:精简描述和定义
- 通过 Hooks 机制在调用前后动态精简/恢复工具规范
- 节省约 72.2% token
- 适用场景:接入大量 MCP 工具的场景
策略二:代码执行
- 将多个 MCP 工具调用封装成一个高层工具,避免中间结果经过模型处理
- 节省约 66.1% token
- 适用场景:多步骤工作流场景
这两种策略并不互斥,实际上可以同时使用。比如在接入大量 MCP 工具的同时,将常用的多步骤工作流封装成代码执行工具,这样可以获得更显著的优化效果。具体的组合实现留给读者自己尝试。
回到文章标题的问题:Agent 时代 MCP 已经过时了吗? 答案显然是否定的。MCP 作为连接 Agent 与外部工具和数据的开放标准,其价值在于提供了统一的集成方式和丰富的生态系统。随着接入工具数量的增长,确实会面临上下文窗口占用和 token 消耗的挑战,但这些问题可以通过更智能的使用方式来解决。





